JProfiler 15.0 introduces the following notable new features:
Probes for Apache Kafka were added. The probes measure various types of data that help you to identify
bottlenecks, optimize configurations, and maintain the health of your data streaming infrastructure.
To handle both client and server separately, there are separate probes for Kafka consumers and Kafka producers.
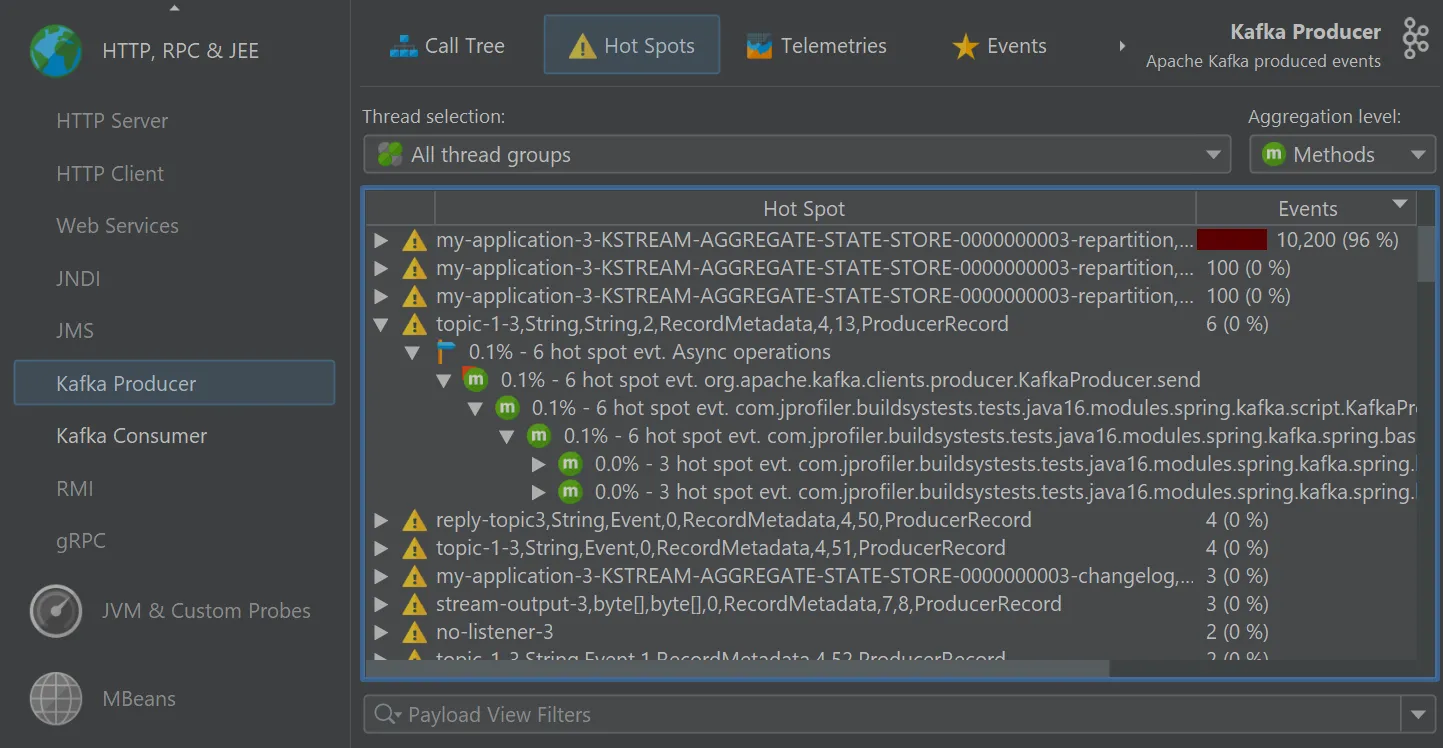
The "Kafka producer" probe analyzes the events that you publish.
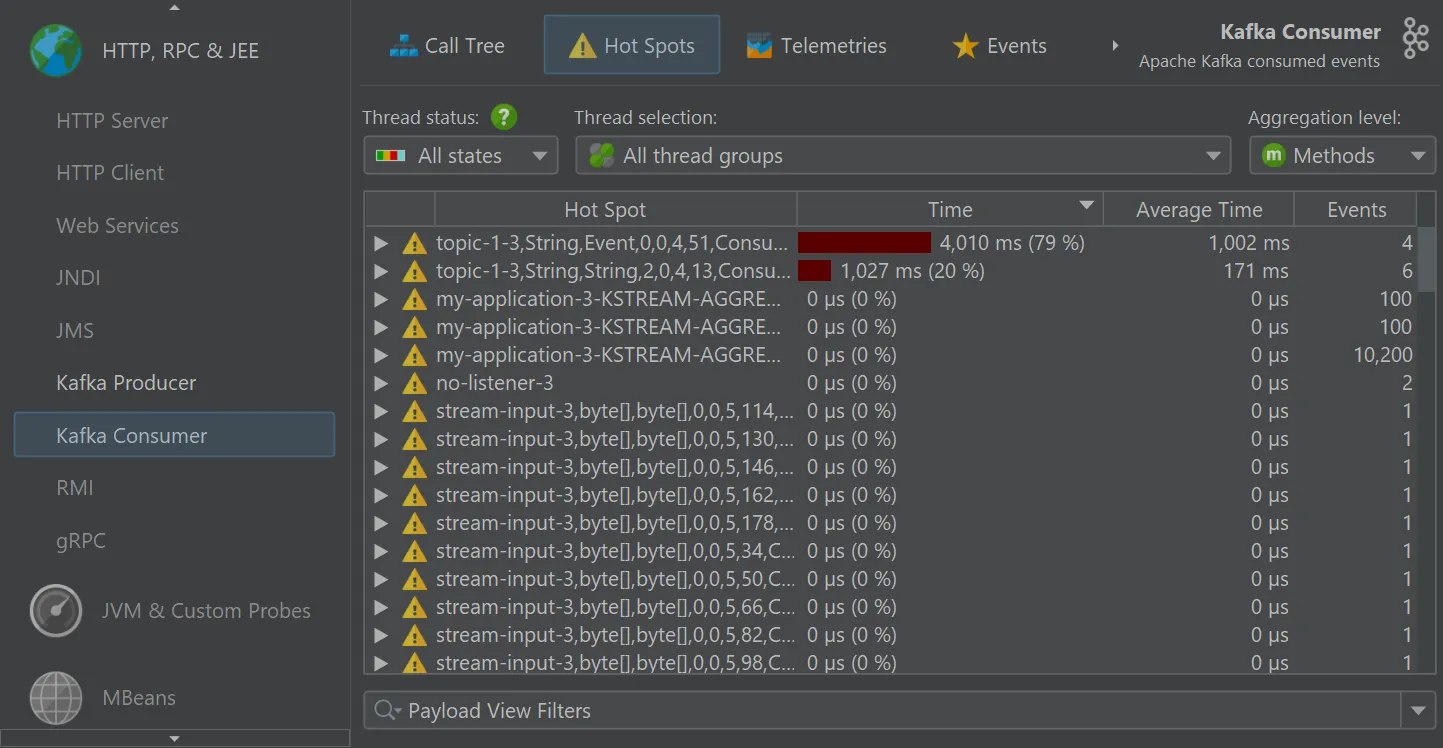
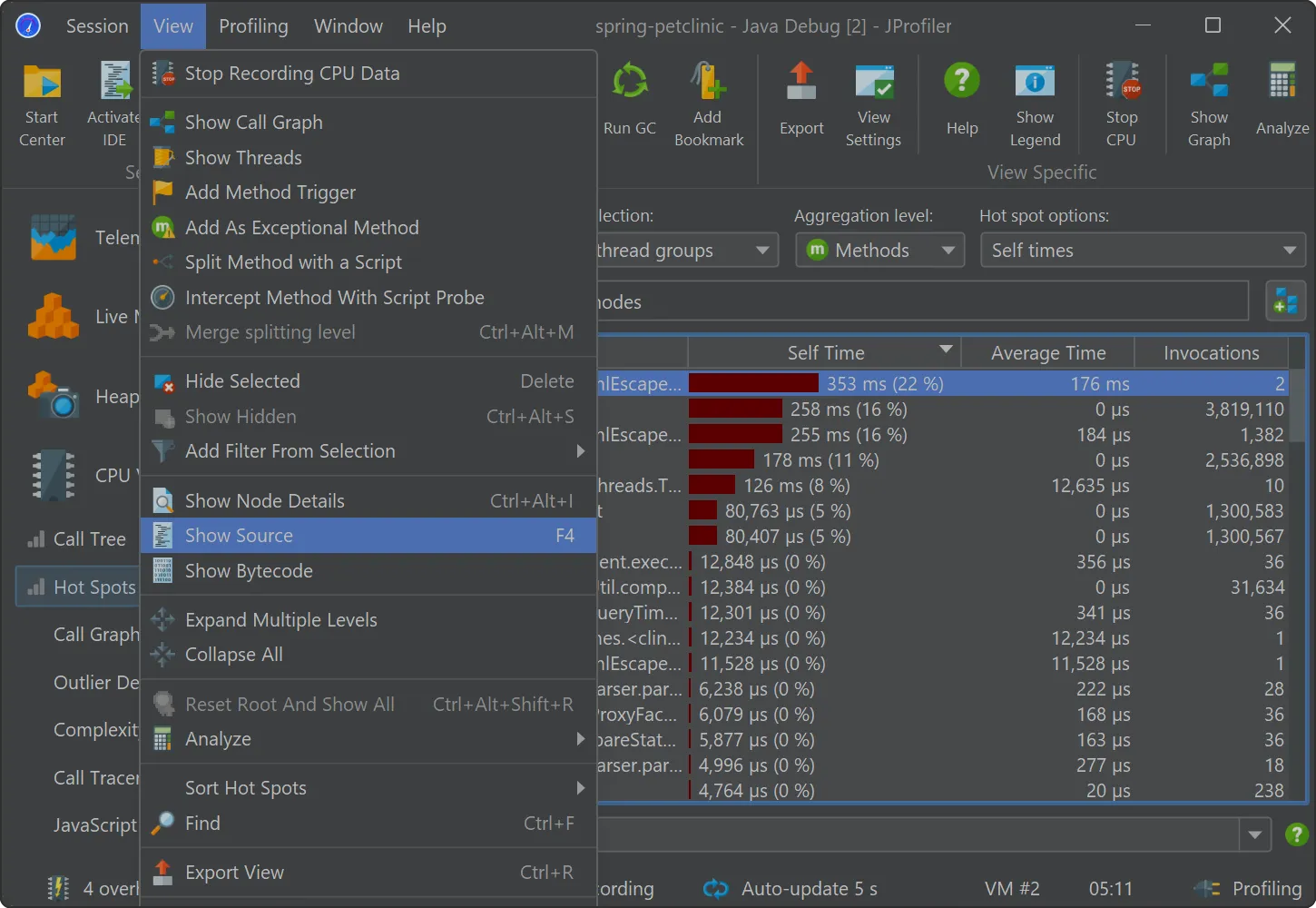
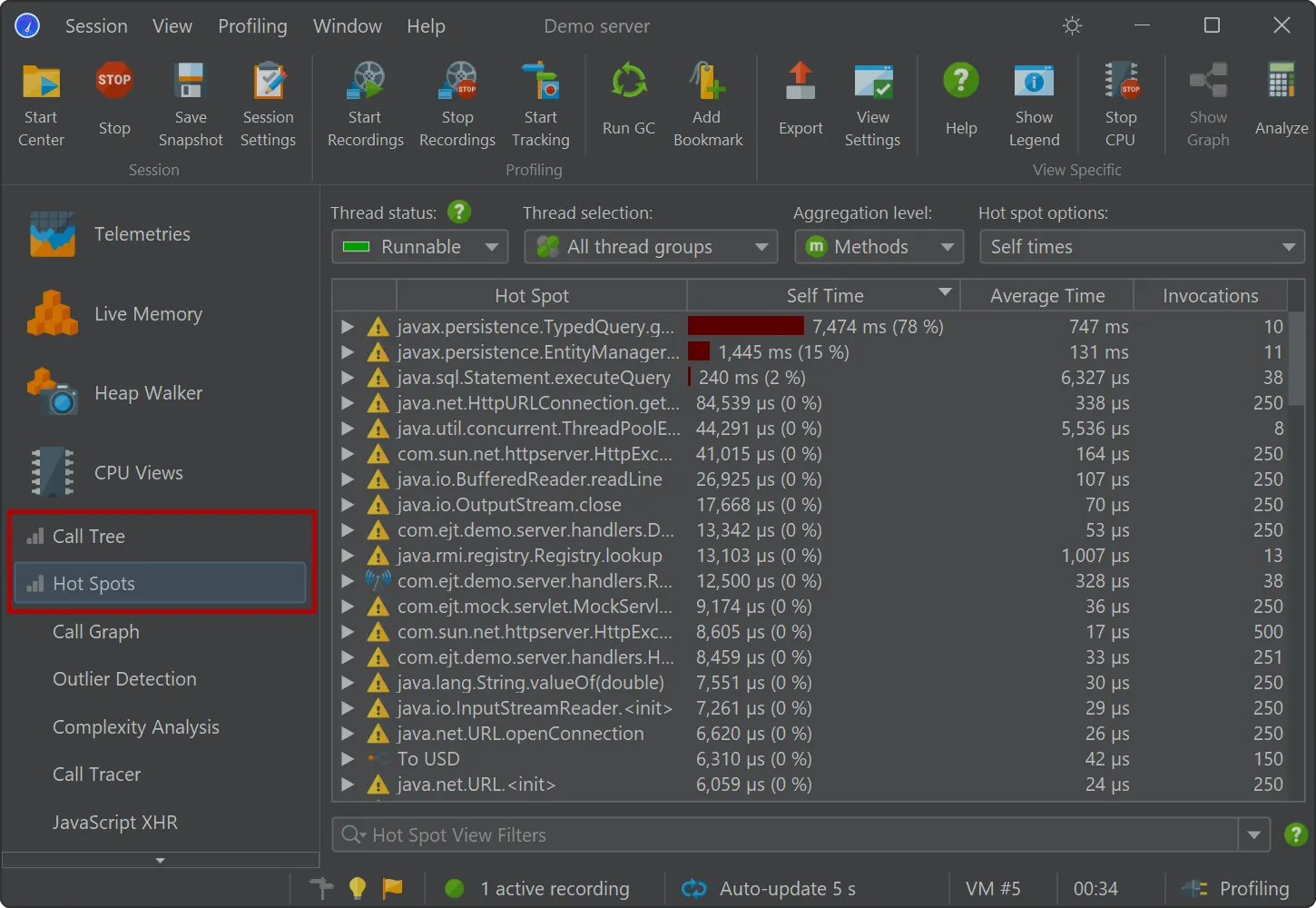
A starting point for handling many kinds of problems is the "Hot spots" view where you can open hot spot nodes to see the back traces
into your code.
The "Kafka consumer" probe measures the events that you process. For Spring Kafka, event timings are recorded.
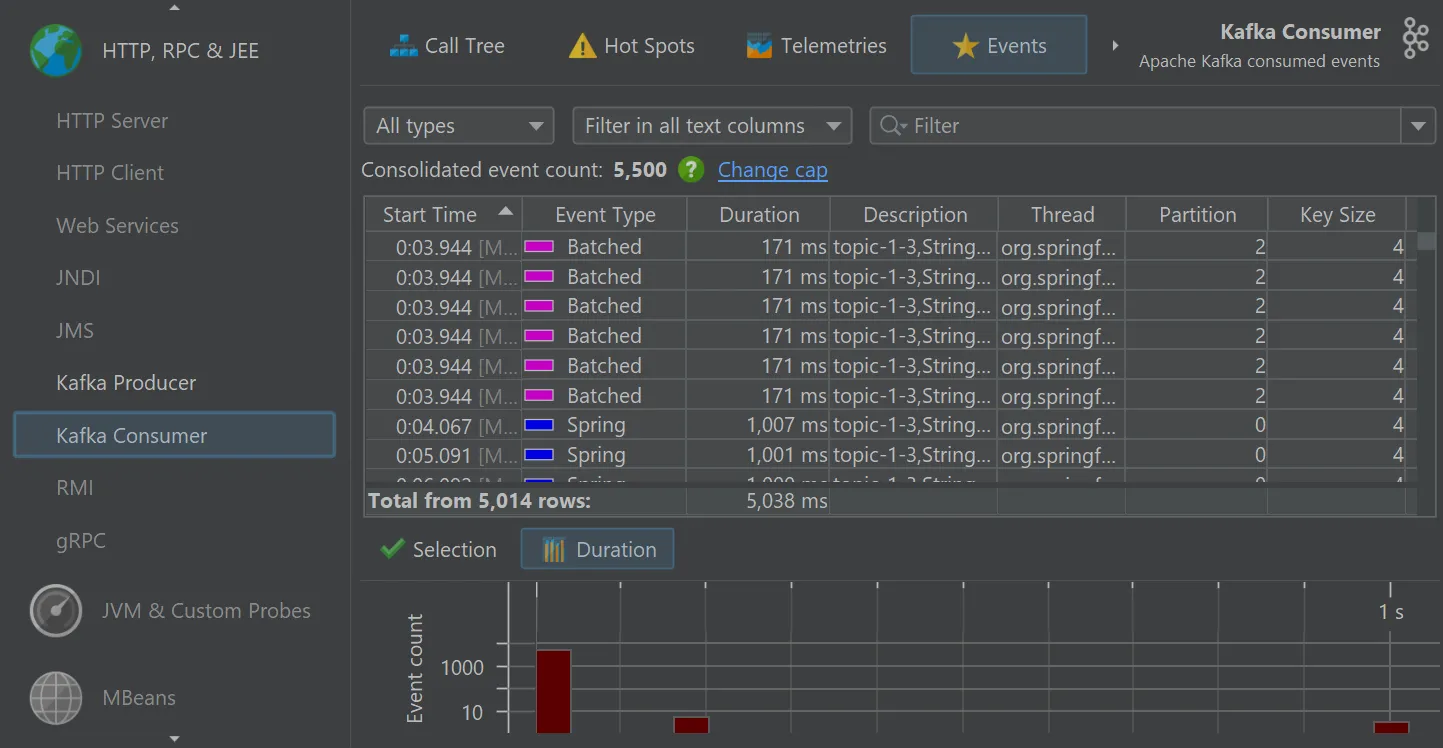
Single events can be analyzed in the "Events" view, where values for event type, thread name, partition, key and value size are also shown.
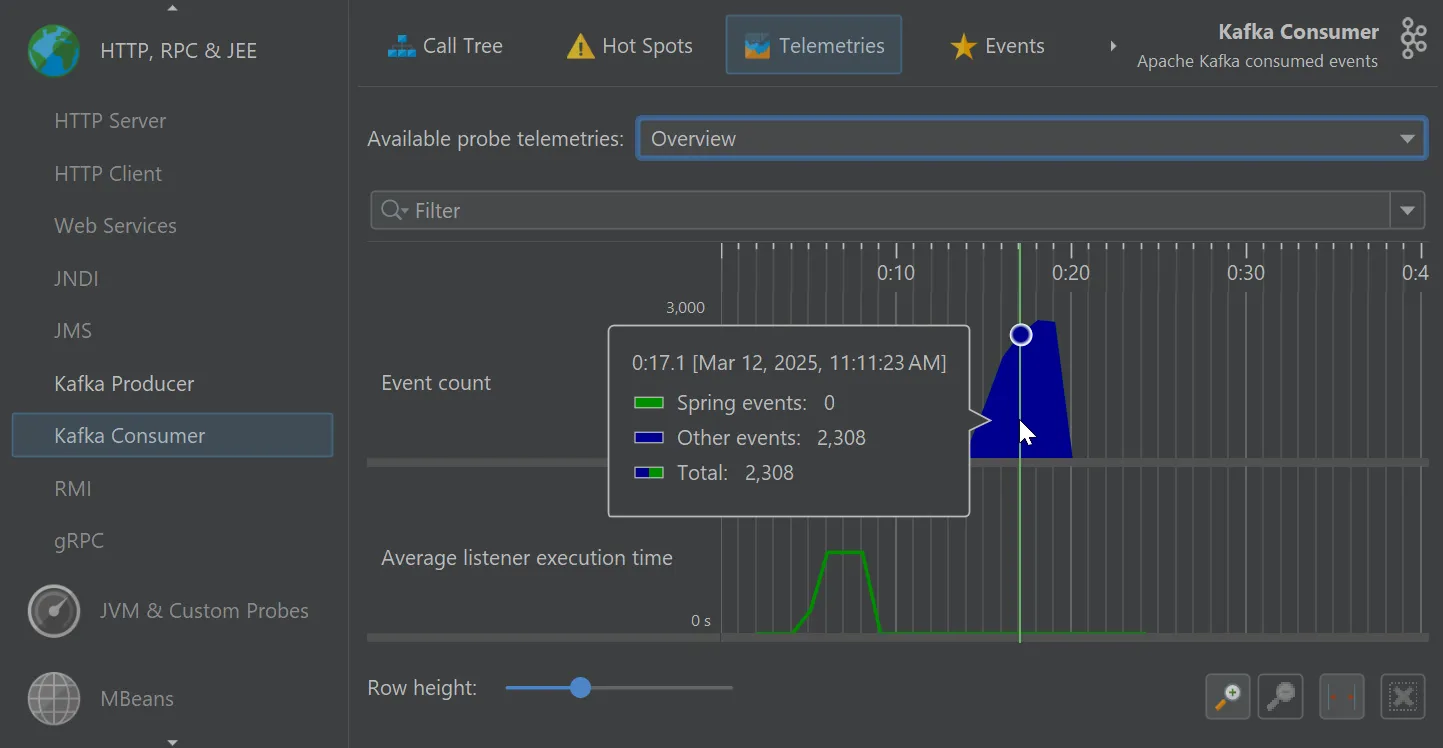
The Kafka probes contribute several telemetries, like "Event count" and "Average listener execution time" that can also be added
in the main "Telemetries" view section.
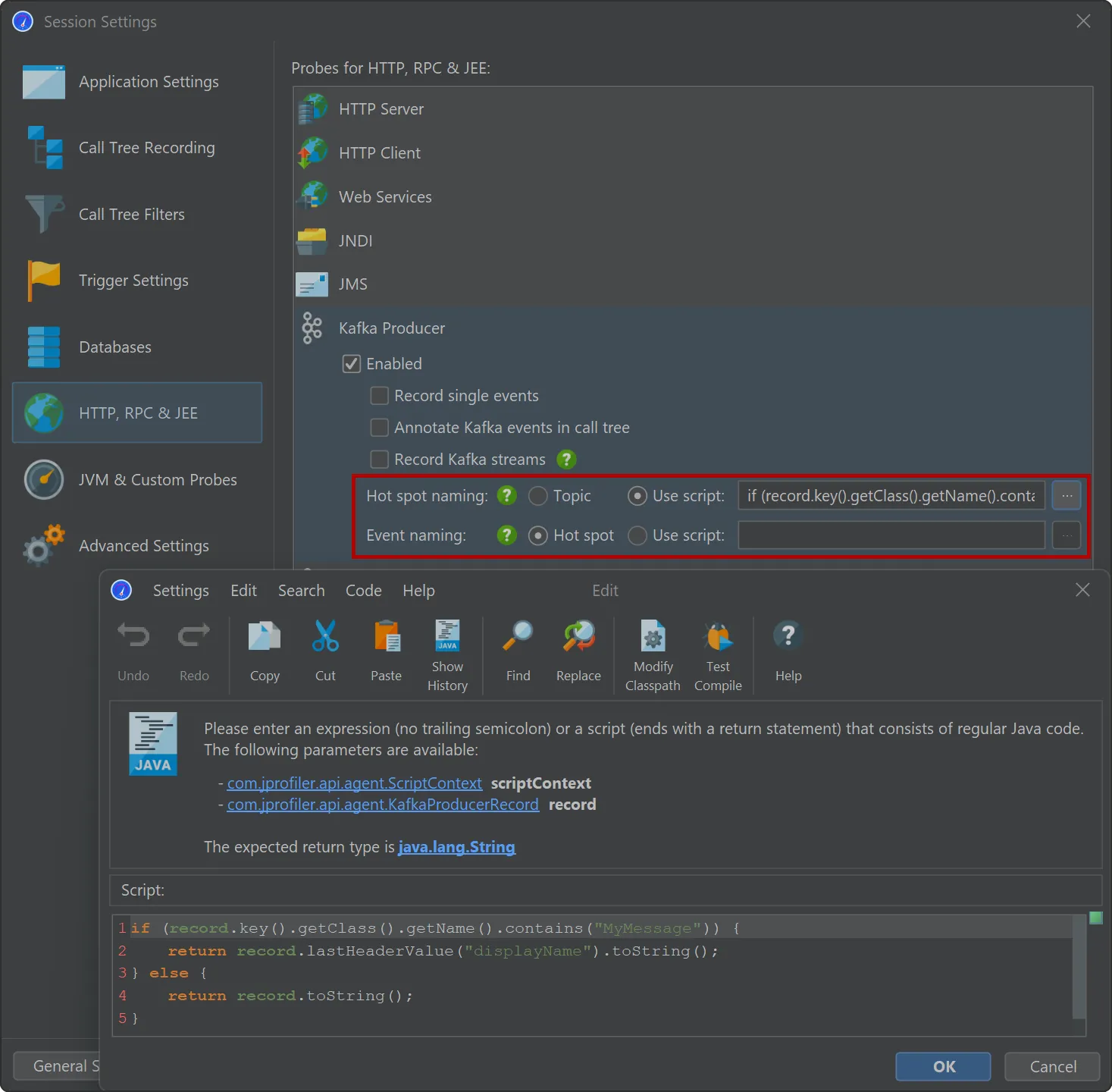
Both probes offer the same flexibility for naming hot spots and events. By default, hot spots are named with the message topic.
You can use a script to build the strings for the hot spots yourself using an API provided by JProfiler. Naming hot spots is important
because it determines the grouping in the hot spots view.
Optionally, you can use a different script for the naming of single events in the "Events" view. This will not affect hot spot grouping
and is a way to provide more detail for debugging.
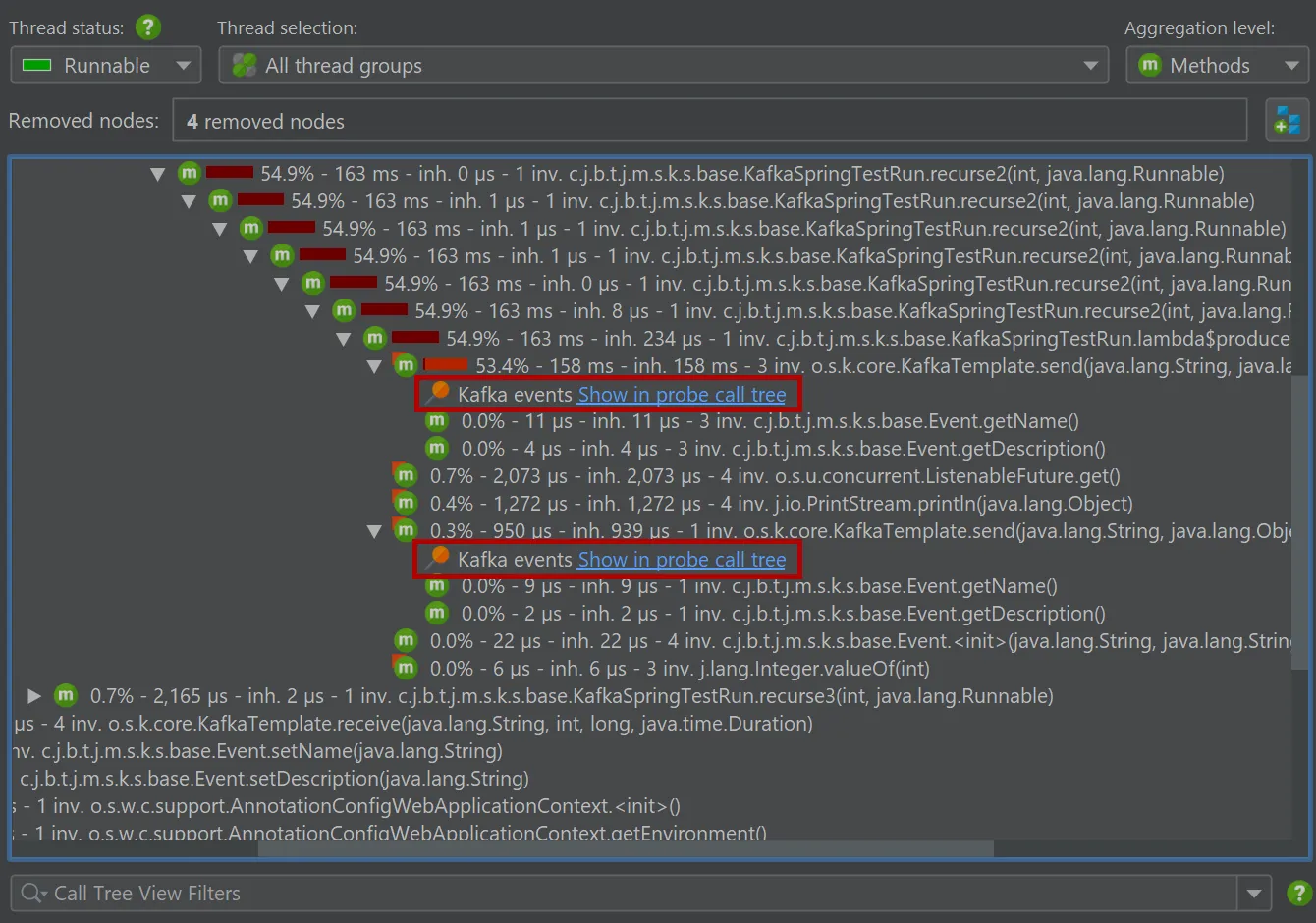
Recording events from either probe adds data in the regular call tree views in the "CPU views section". For the "Kafka producer" probe,
hyperlinks are inserted into the call tree for revealing the associated call stack in the call tree view of the probe.
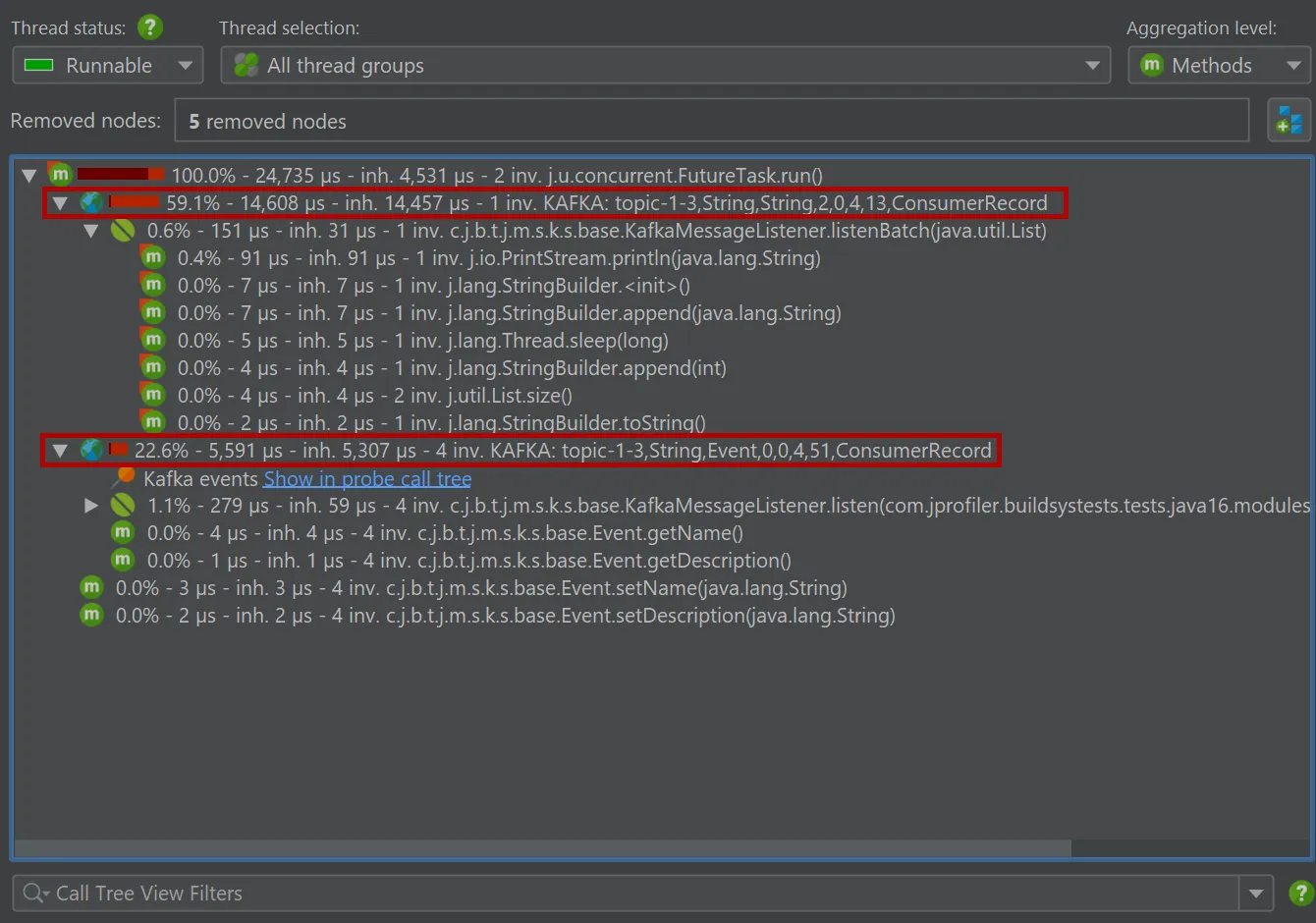
The Kafka consumer probe splits the call tree for Spring event listeners, so you can see the subtree for different types of messages
separately. The grouping is done with the configured "hot spots" naming.
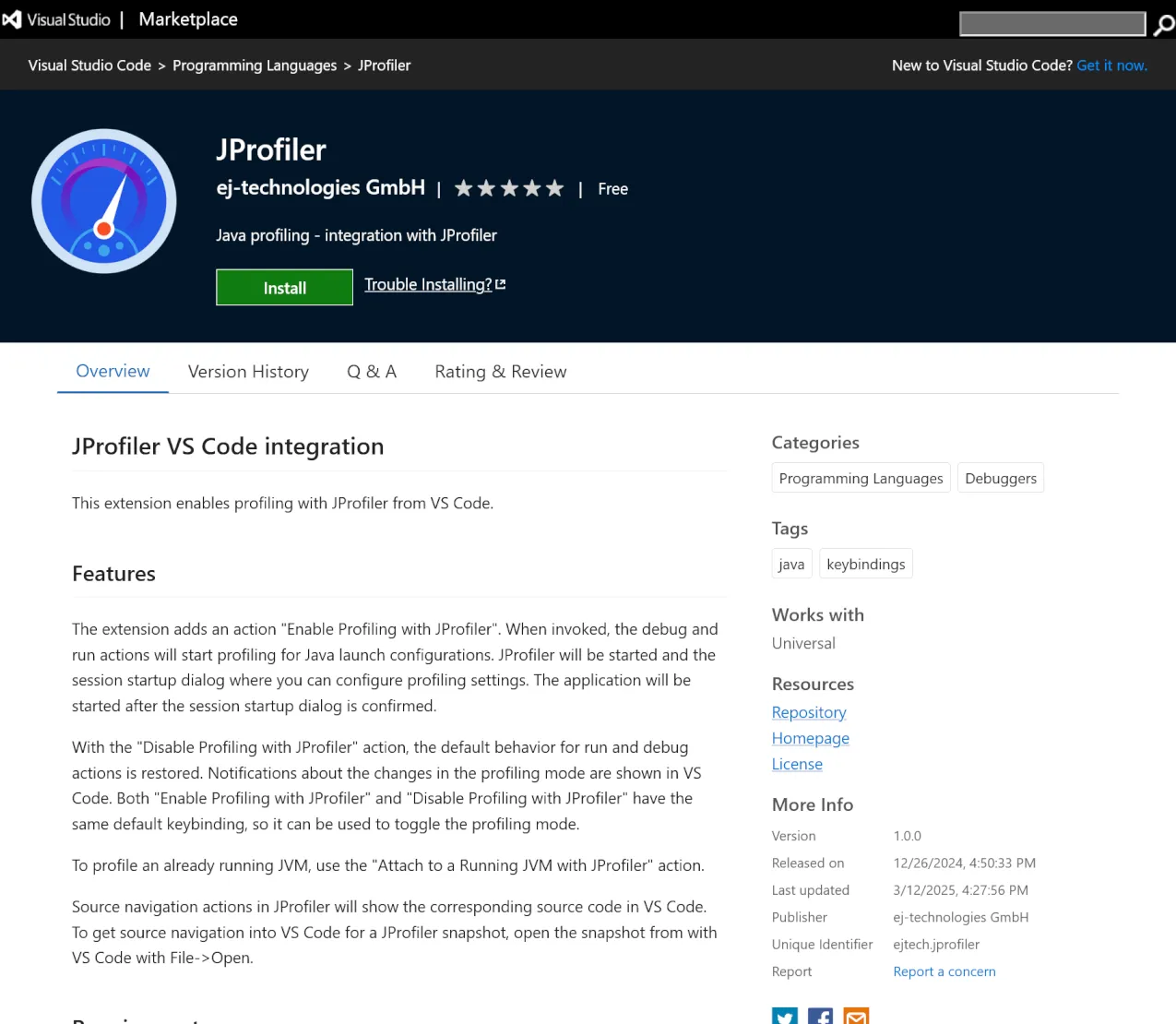
An IDE integration for Visual Studio Code has been added. It is available in the
Visual Studio Marketplace and works together with a
local installation of JProfiler.
If the VS Code plugin cannot find the JProfiler installation automatically, it will ask you to locate it the first time you start a profiling
session.
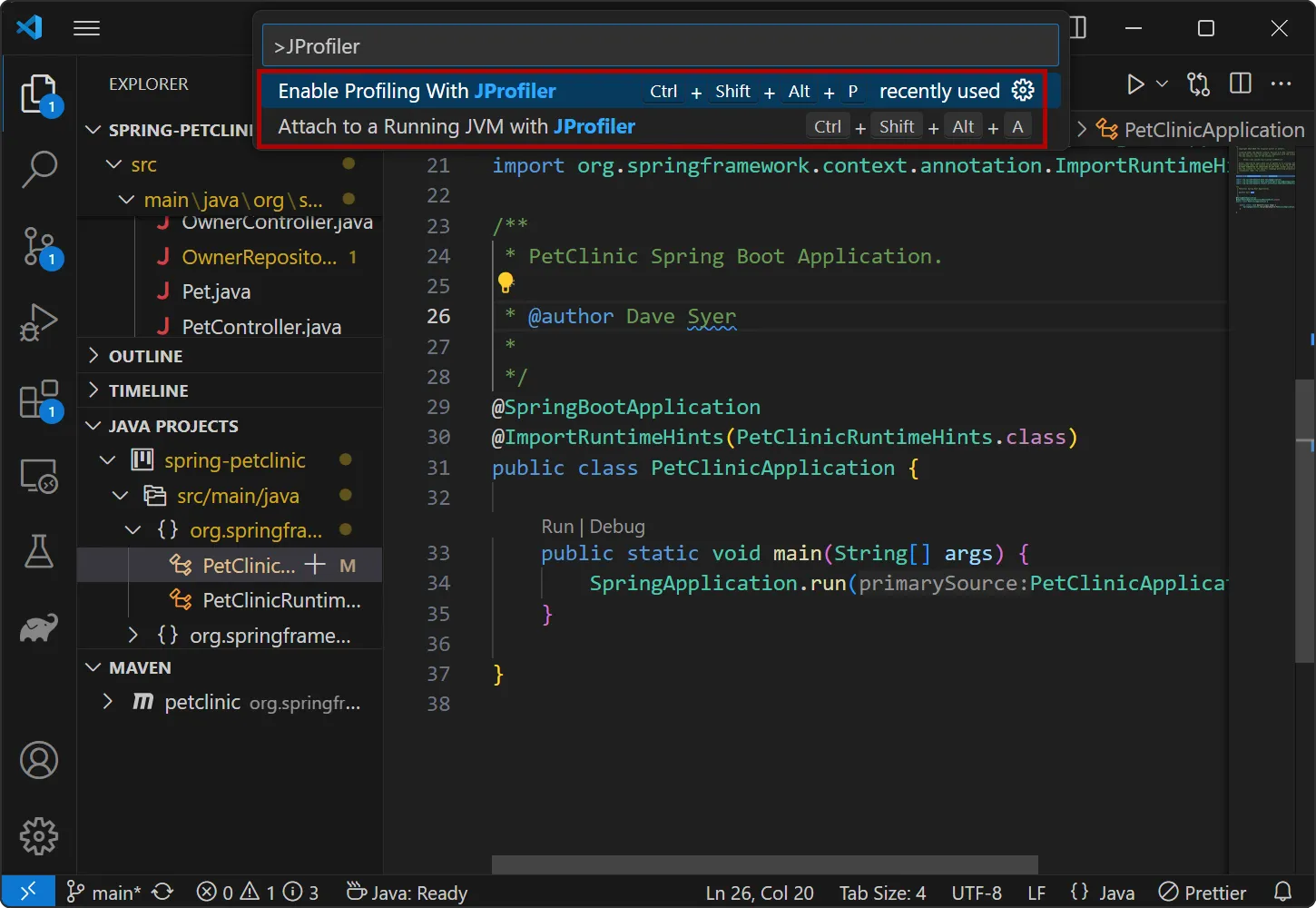
The extension adds two actions: With "Enable Profiling with JProfiler" you toggle the profiling mode, so that all debug and run actions
will start profiling for Java launch configurations. With "Attach to a running JVM with JProfiler" you can use the attach mode feature for
local or remote JVMs and get source code navigation into VS code.
Depending on the status of this pull request for the vscode-gradle
plugin, profiling Gradle tasks is also supported by the "Enable Profiling with JProfiler" action.
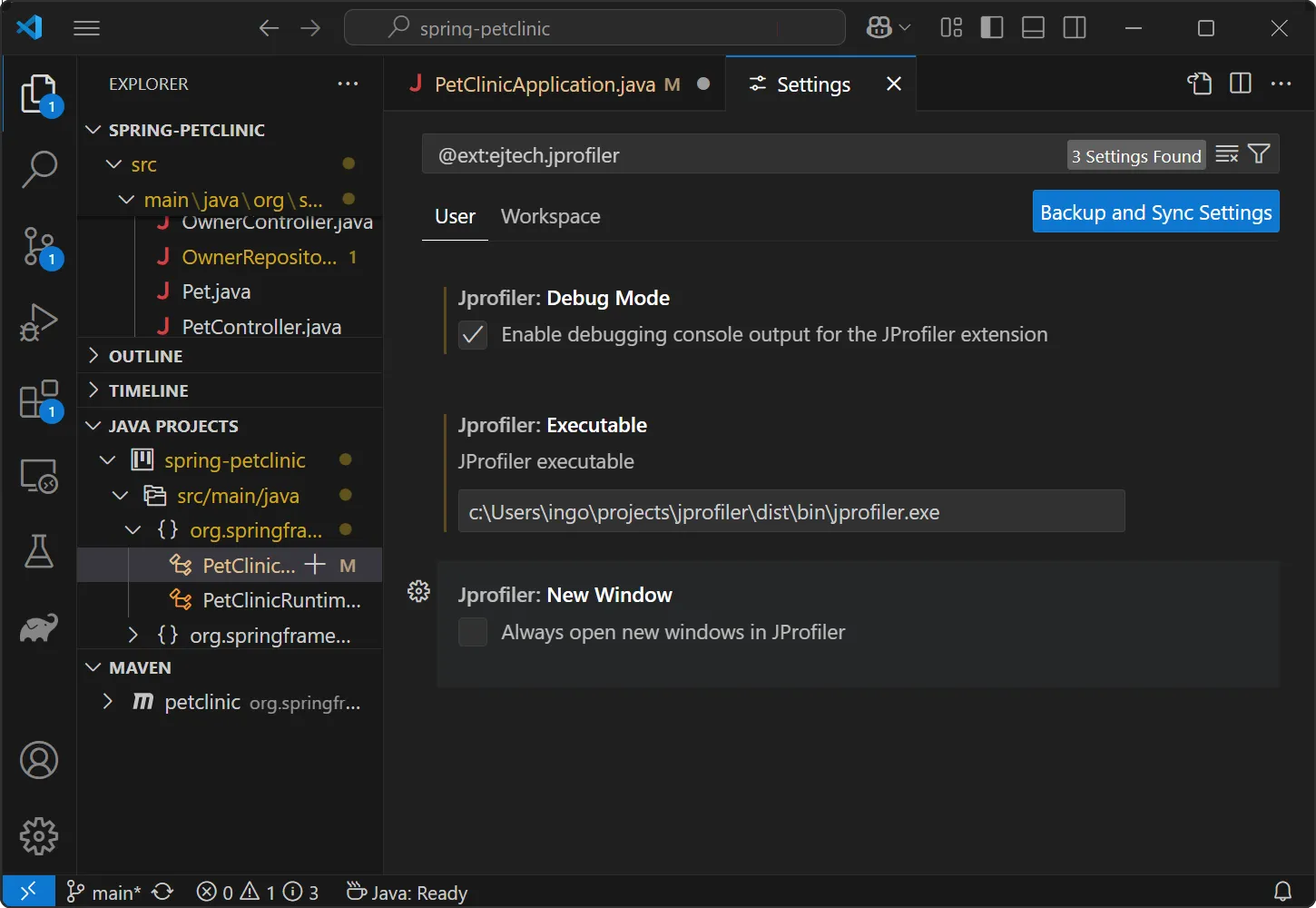
The JProfiler plugin only has a few settings, notably for the location of the JProfiler executable and a setting whether to open new windows
for new profiling sessions.
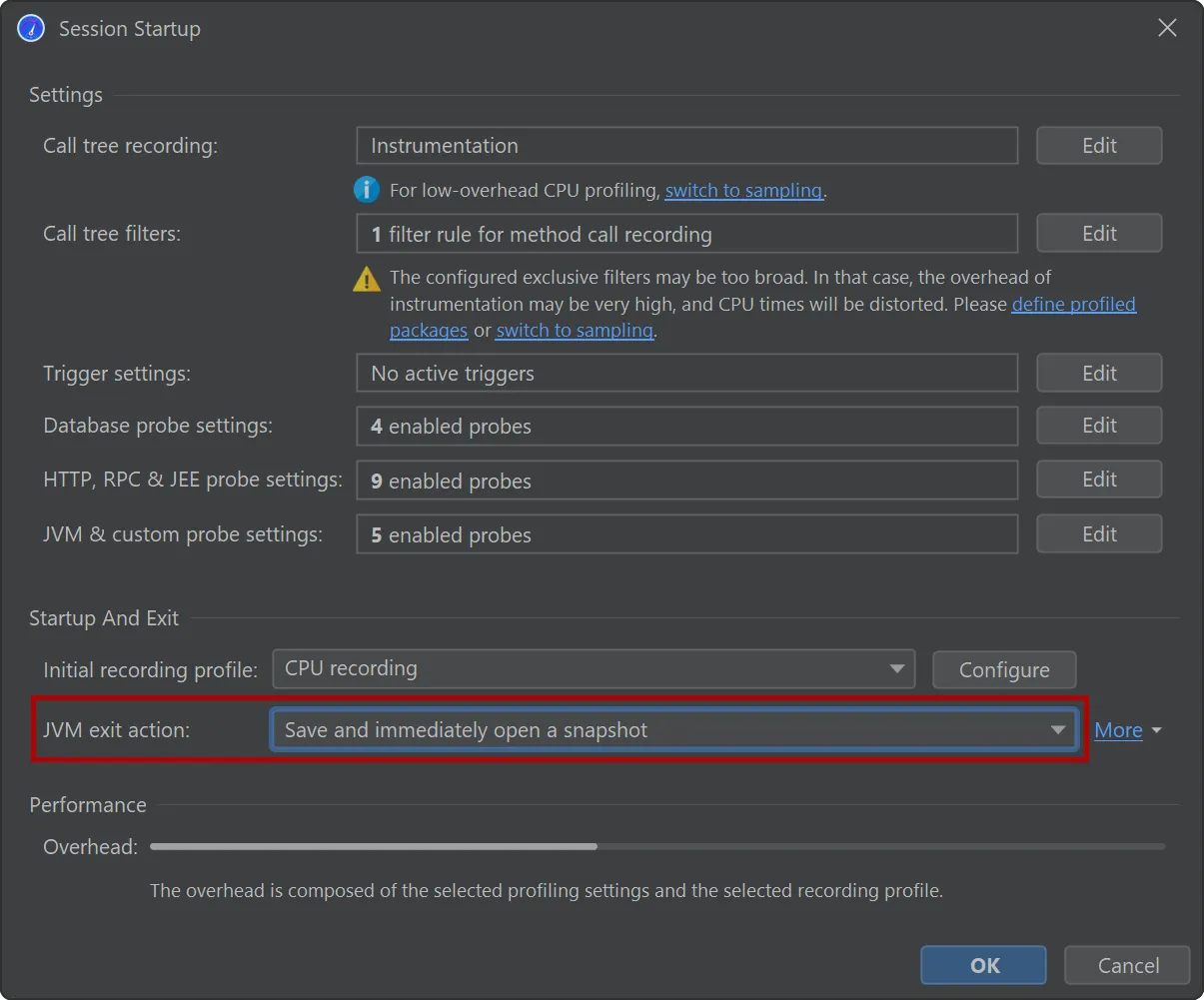
All other profiling settings are handled by JProfiler and stored on a per-project basis. When you start a profiling session, the
session startup dialog gives you a chance to view and modify all settings in one place.
When profiling unit tests, JProfiler will automatically suggest saving and immediately opening a snapshot when the JVM exits.
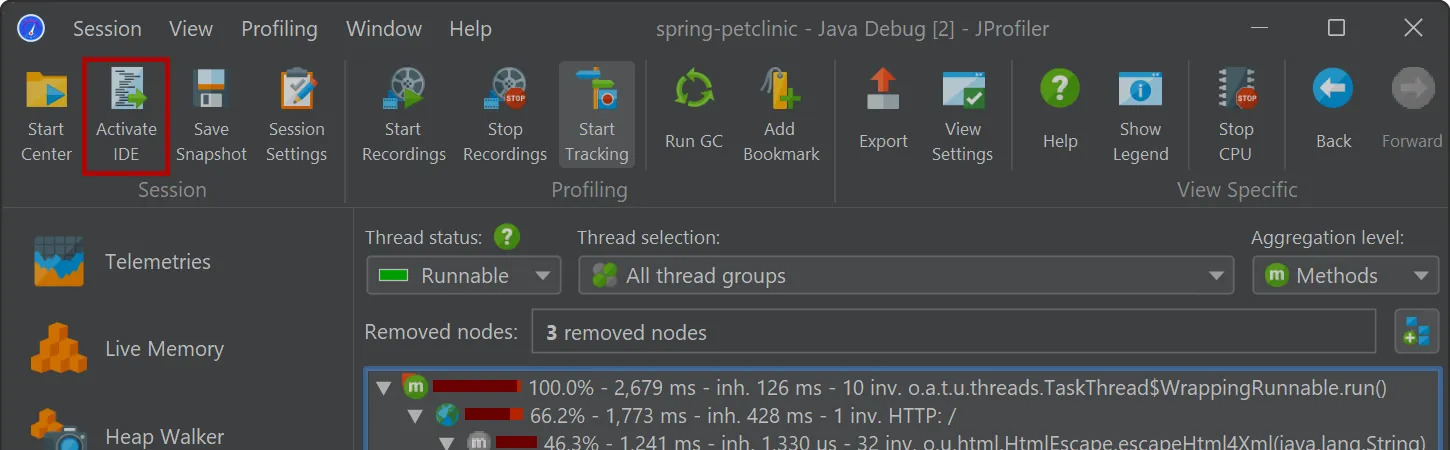
Switching to VS code when working with the JProfiler UI is seamlessly possible with the "Activate IDE" action (F11).
To show the source code of a selected class or method, use the "Show source" action that is visible everywhere in JProfiler. The VS
Code UI will be brought to the front, and the associated source code will be shown.
Another useful feature provided by the JProfiler VS Code plugin is that you can open JProfiler, HPROF and PHD snapshots from inside
VS Code to get source code navigation from the JProfiler UI into VS Code.
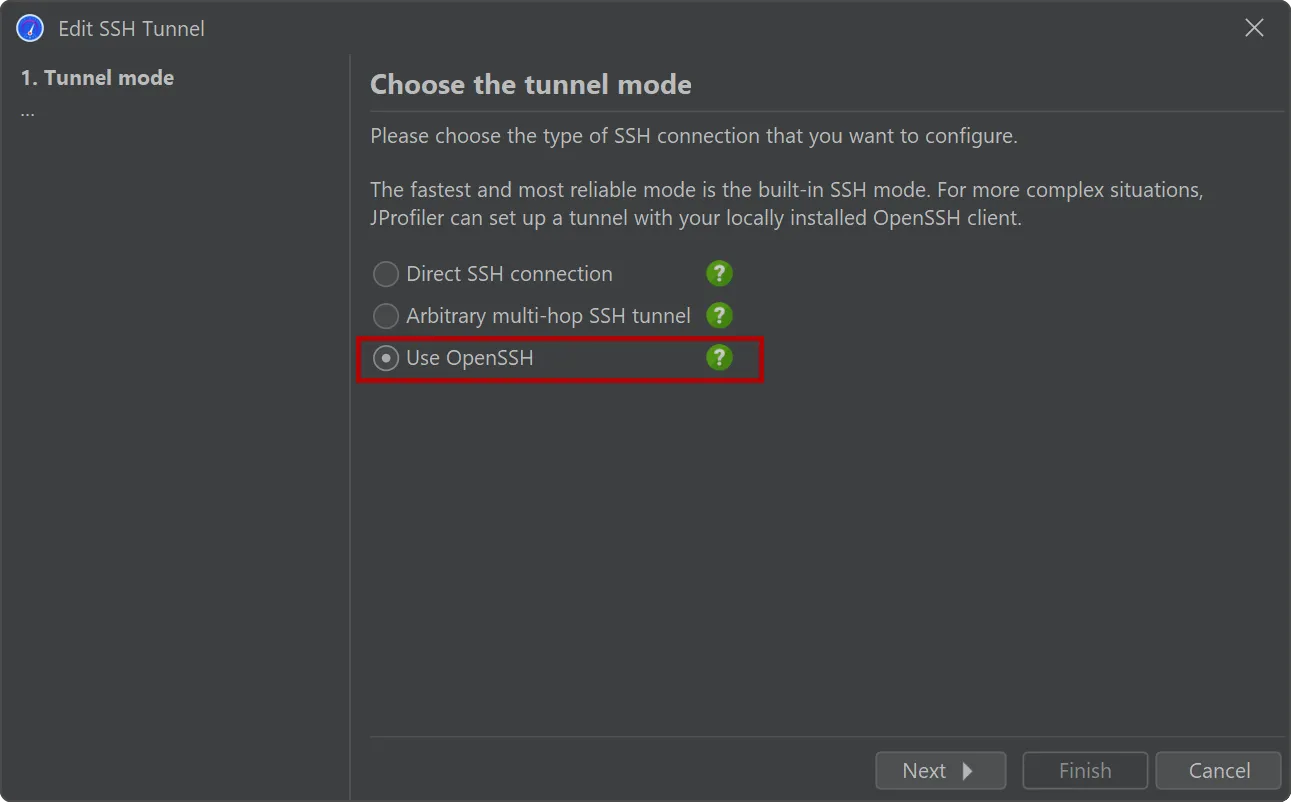
An alternative SSH mode via OpenSSH has been added. This is important for being able to profile JVMs on all types of remote
machines without any configuration.
JProfiler ships with a built-in SSH client for SSH connections that supports password and public key authentication. To support
other authentication types and complex network topologies, a new SSH tunnel type was added, that uses your local OpenSSH installation.
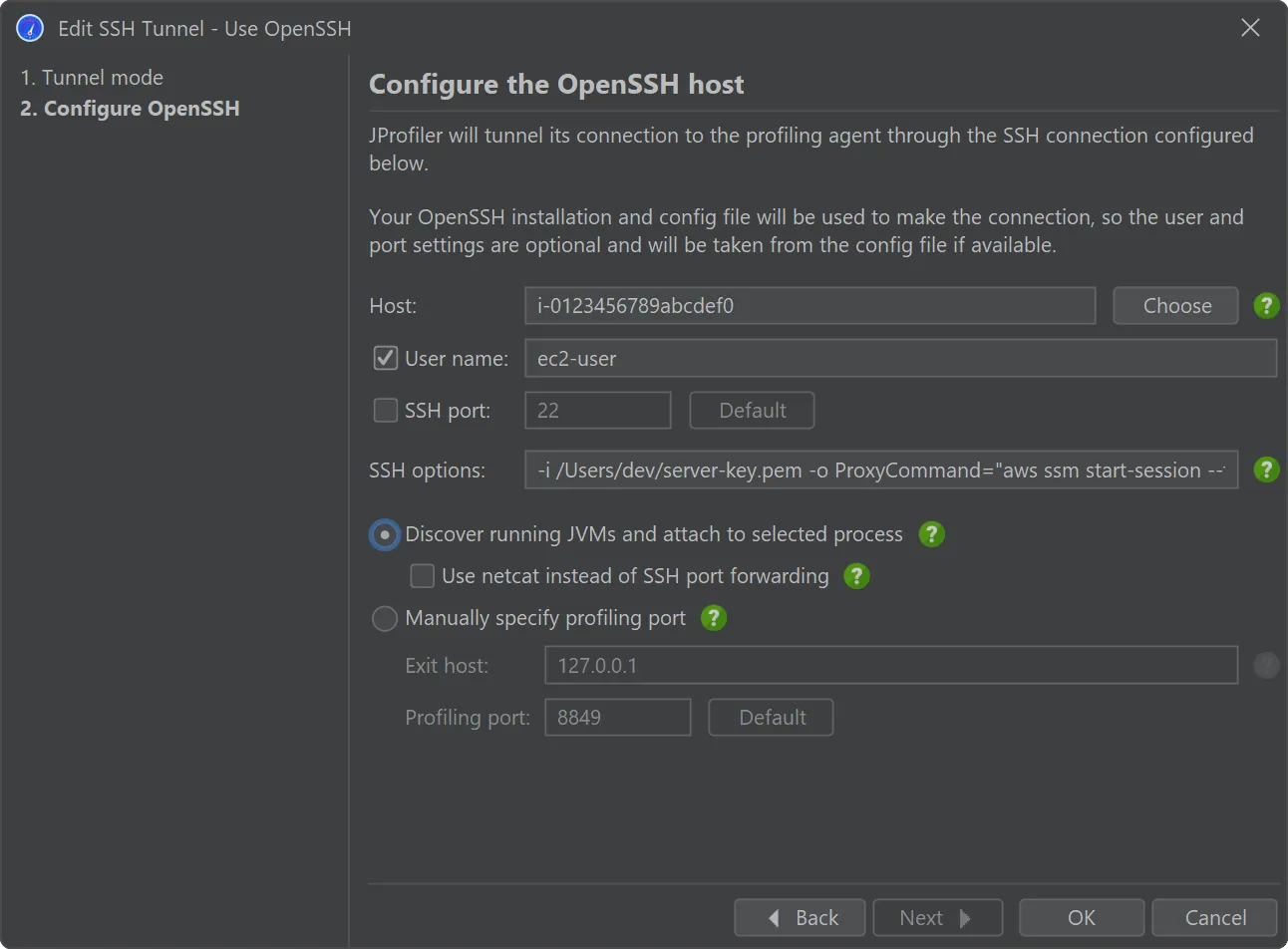
For example, if you want to connect to an EC2 instance via AWS session manager, the built-in SSH client does not work because it cannot
tunnel through an arbitrary proxy. In the
AWS documentation,
you get a list of options that you can either add to the OpenSSH config file or directly on the command line, both of which work with the
new OpenSSH mode in JProfiler. This involves a ProxyCommand option that tunnels the connection through the aws
executable. In the screenshot below, the "SSH options" text field contains these arguments.
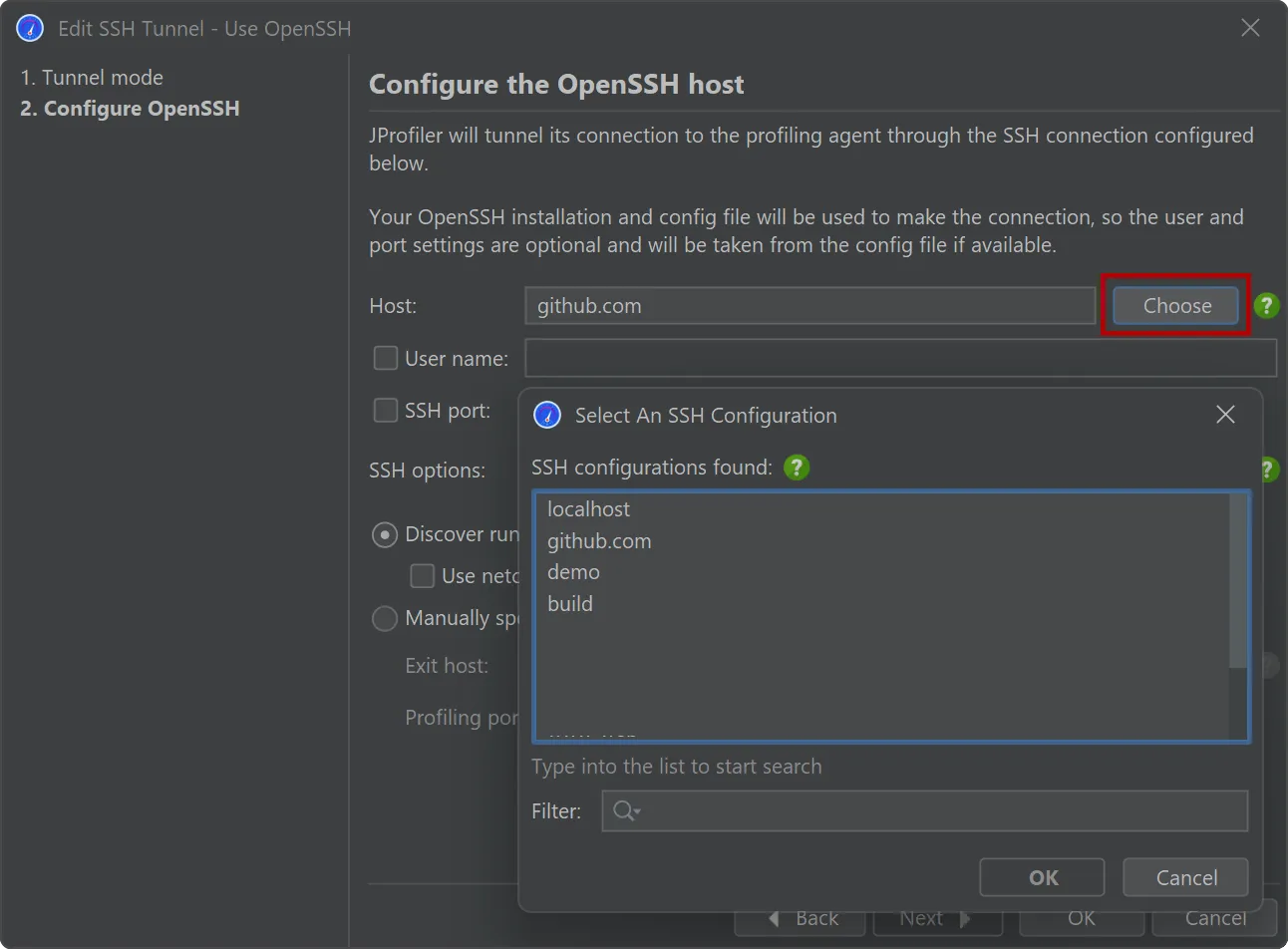
The only required input for the OpenSSH mode is the host name.
In the case where you use the OpenSSH config file to define your fully configured SSH servers, you can easily
select them with the "Choose" button next to the "Host" text field.
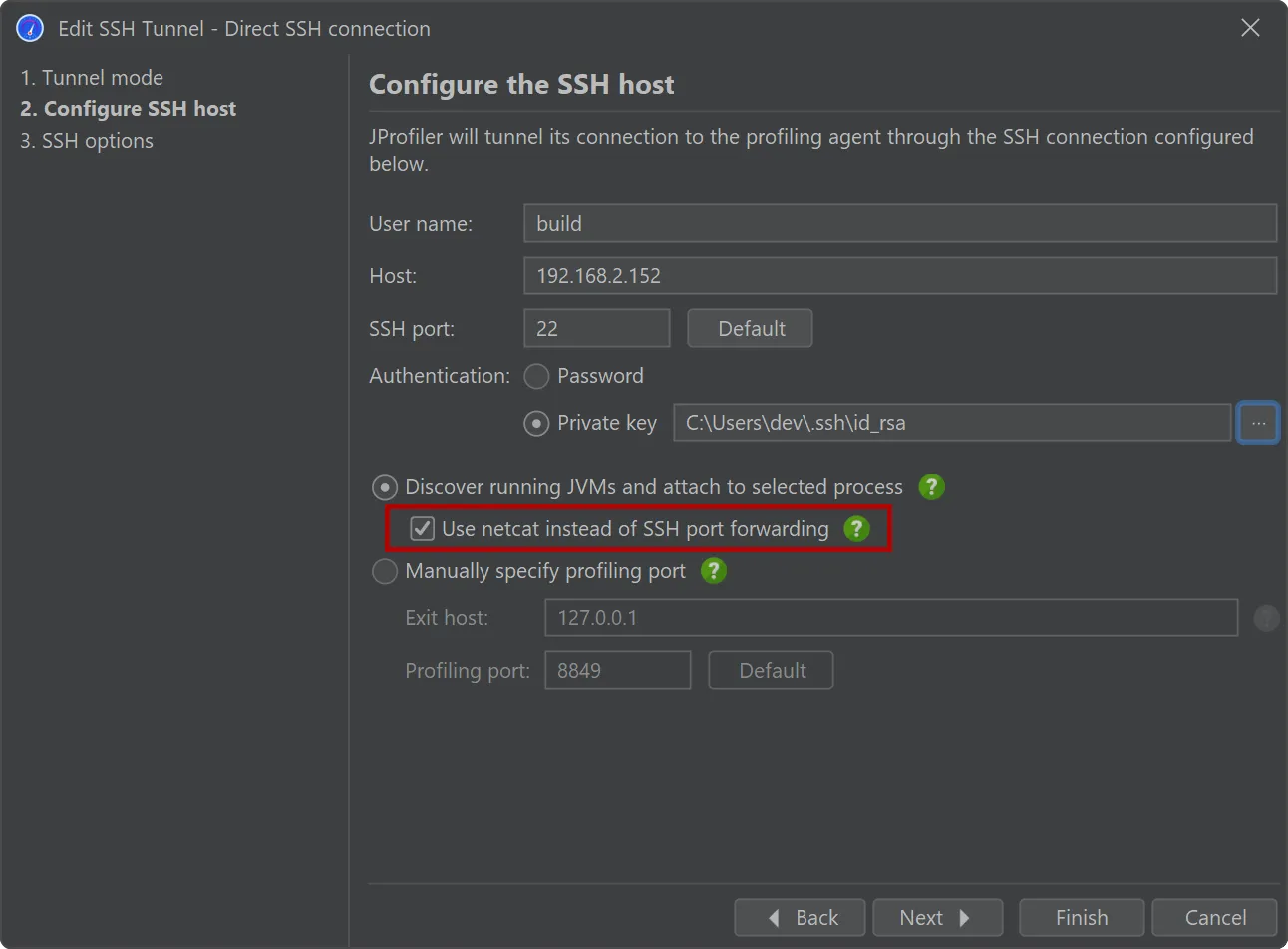
An alternative netcat SSH mode has been added for SSH hosts where port forwarding is disabled.
Many security-hardened production systems disable SSH port forwarding. In those cases, previous versions of JProfiler could not establish
an SSH tunnel through such machines. While SSH port forwarding is still the preferred option for SSH connections due to its stability and
better error reporting, JProfiler 15 adds a "netcat mode" that can optionally be enabled to fix this issue.
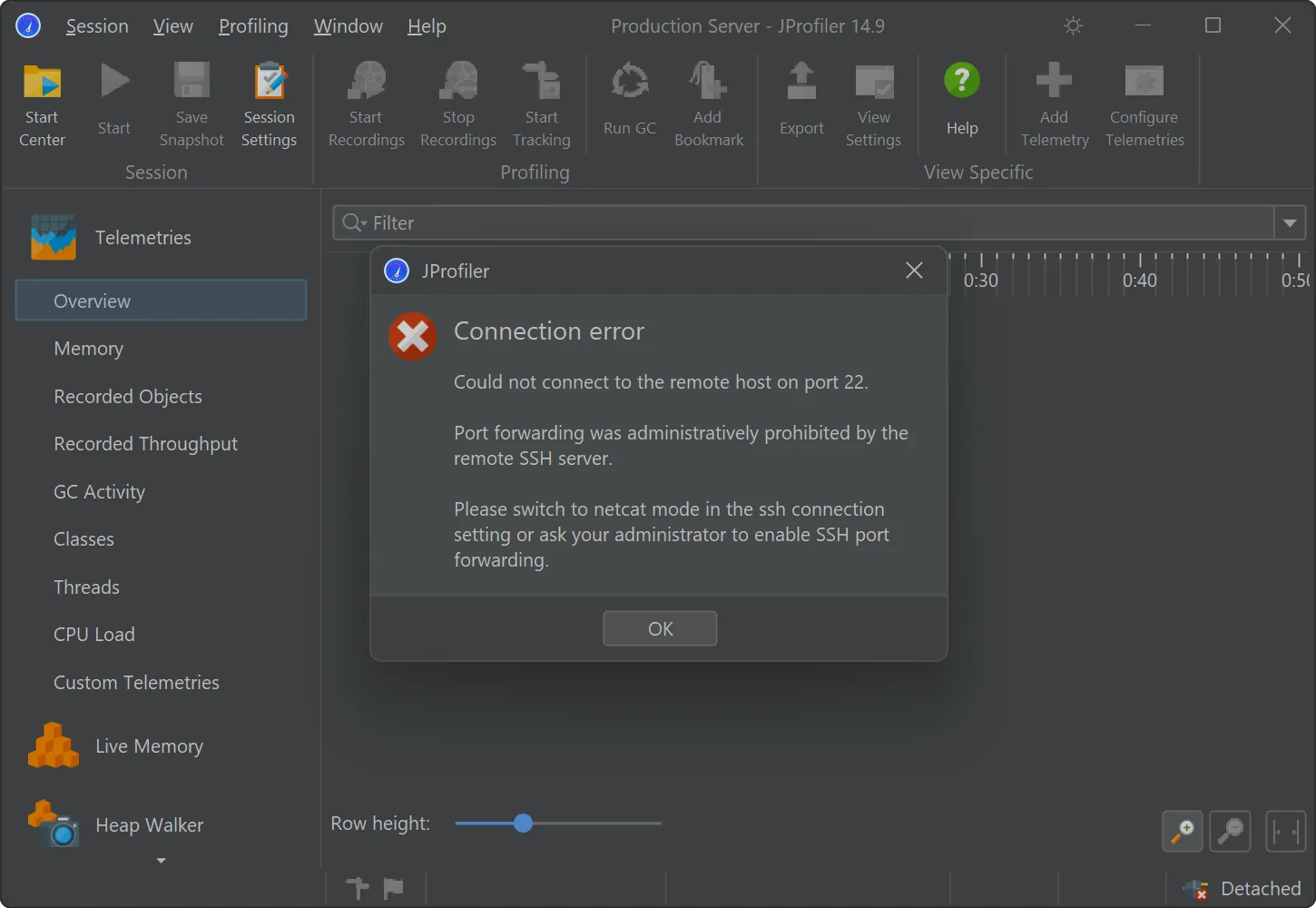
When a connection fails in such a way that disabled port forwarding may be to blame, JProfiler suggest switching to the netcat mode.
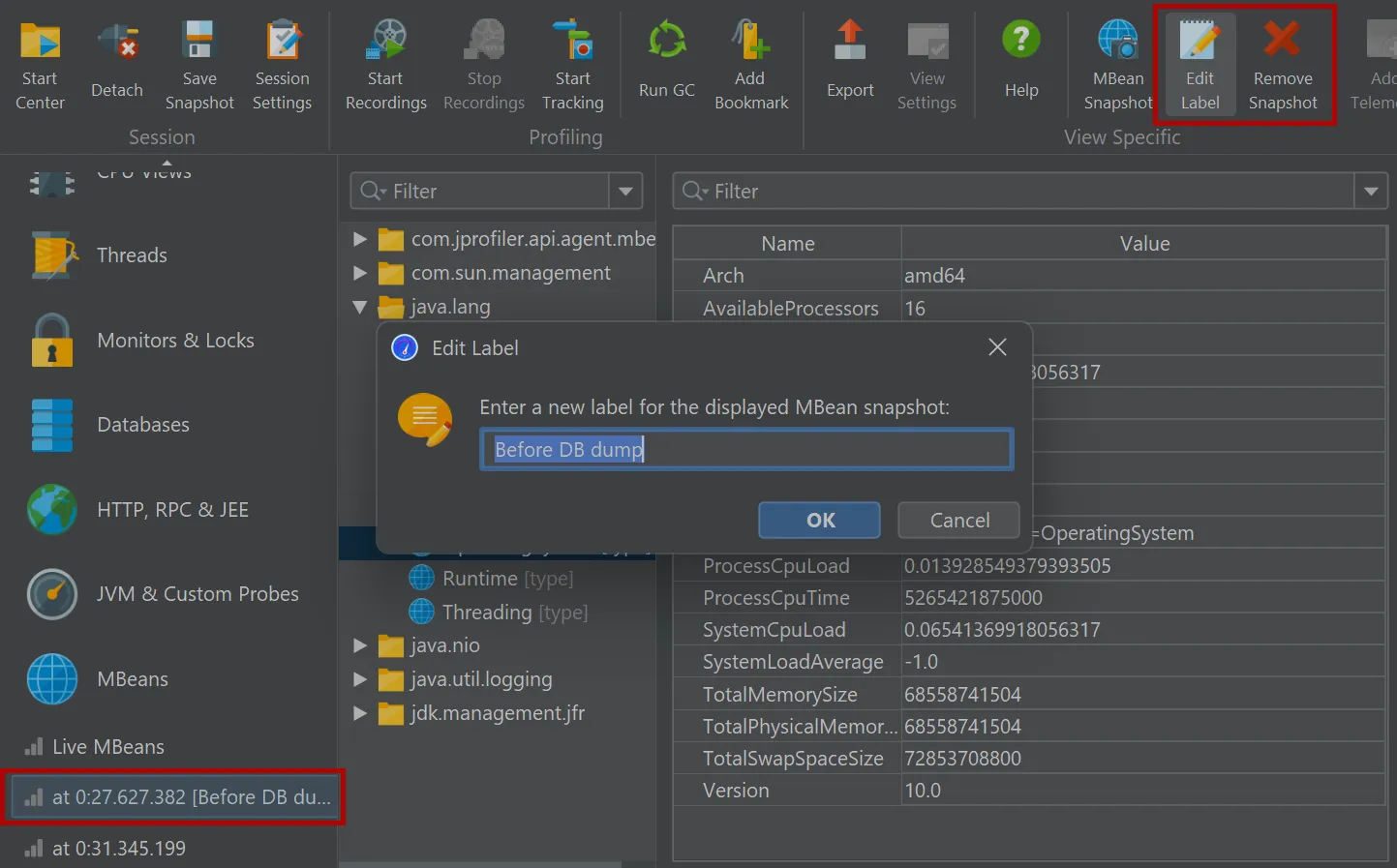
JProfiler can now take MBean snapshots. This is especially useful if you save JProfiler snapshots, either from the UI
or during offline profiling. MBean snapshots enable you to use the MBean browser when JProfiler is not attached to the live JVM.
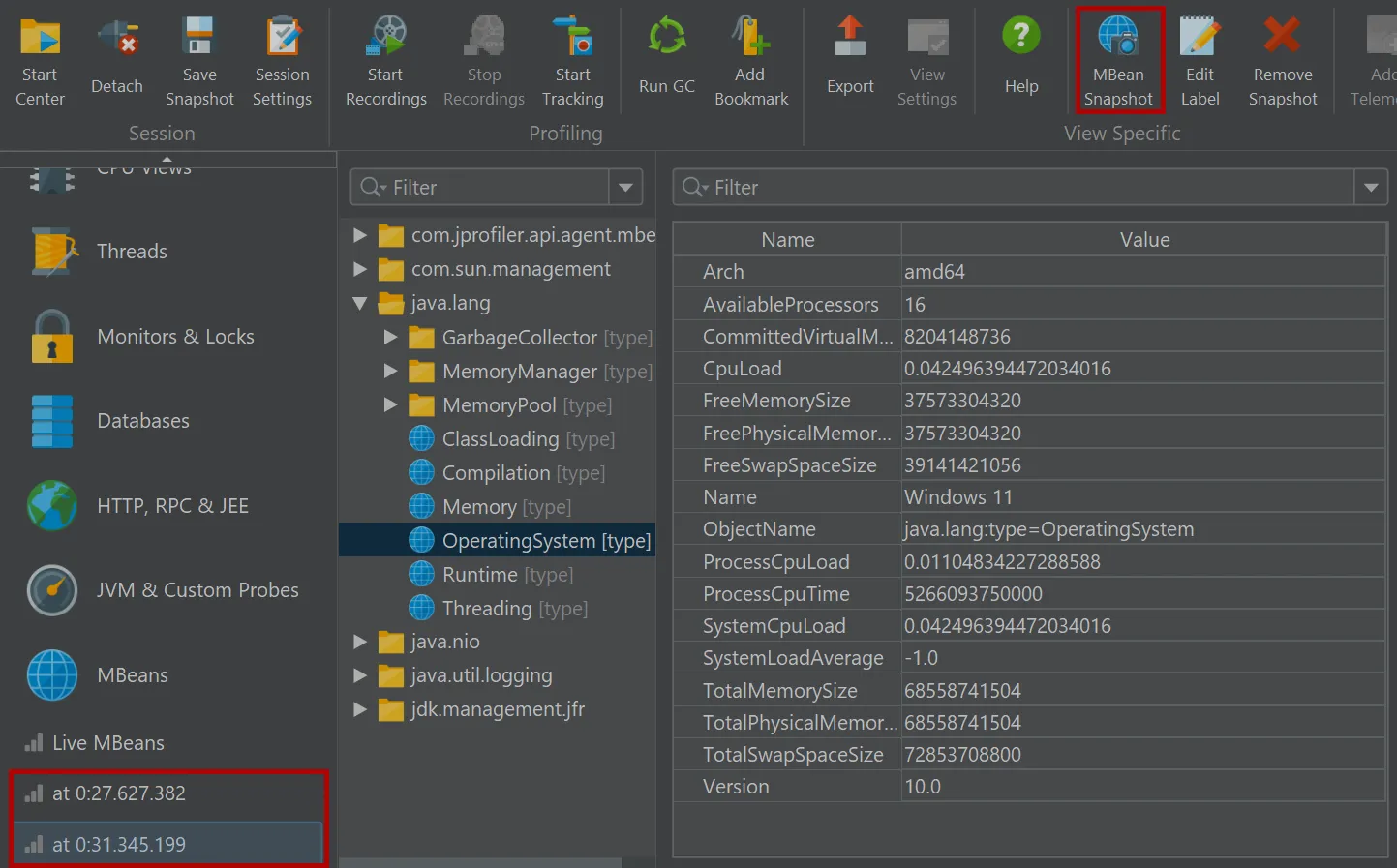
In live mode, the "MBean snapshot" action in the toolbar creates a new snapshot that is then shown in the view selector. You can take
multiple snapshots and switch between them.
MBean snapshots can be assigned labels that are displayed in the view selector. Unwanted MBean snapshots can also be removed again.
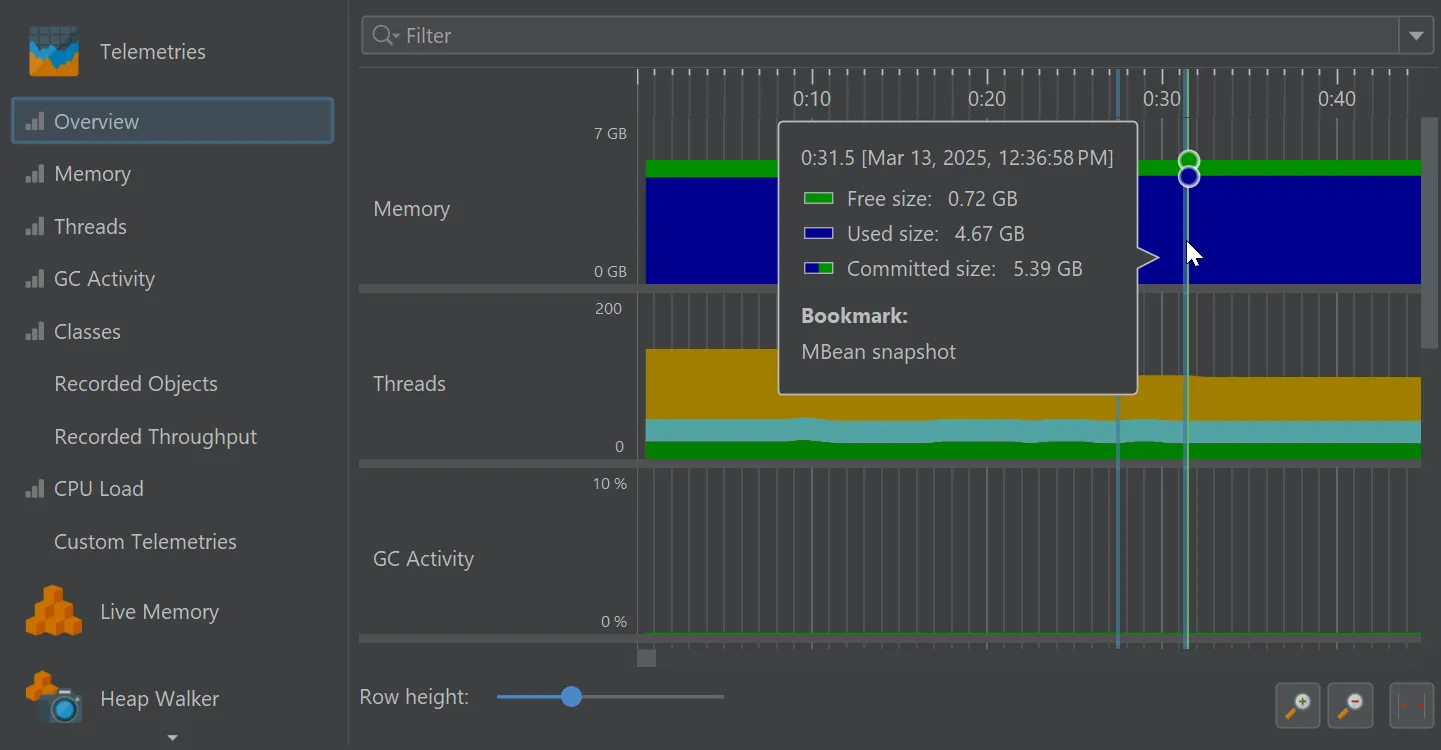
When you take an MBean snapshot, a bookmark is added to all views that have a time axis.
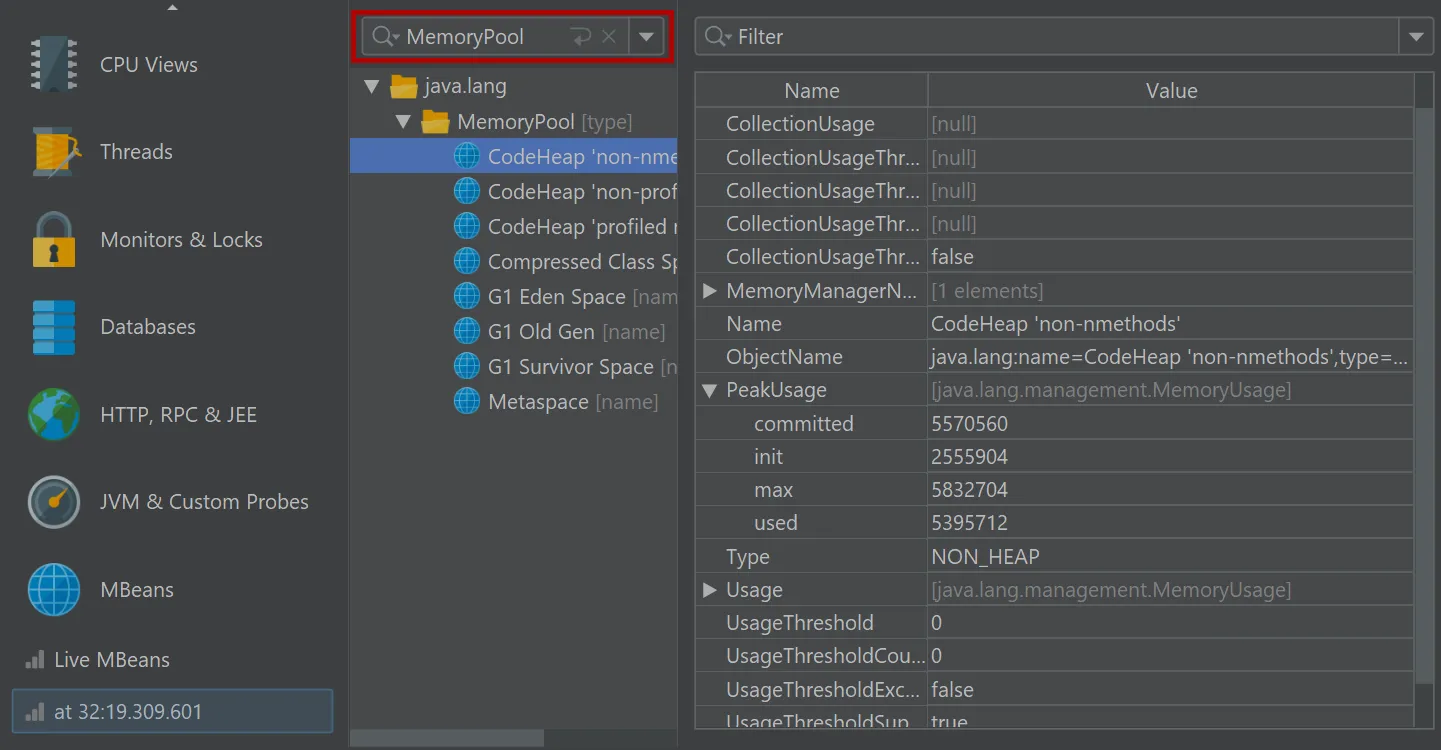
If you set a filter for the displayed MBeans, only the displayed subtrees will be included in the snapshot.
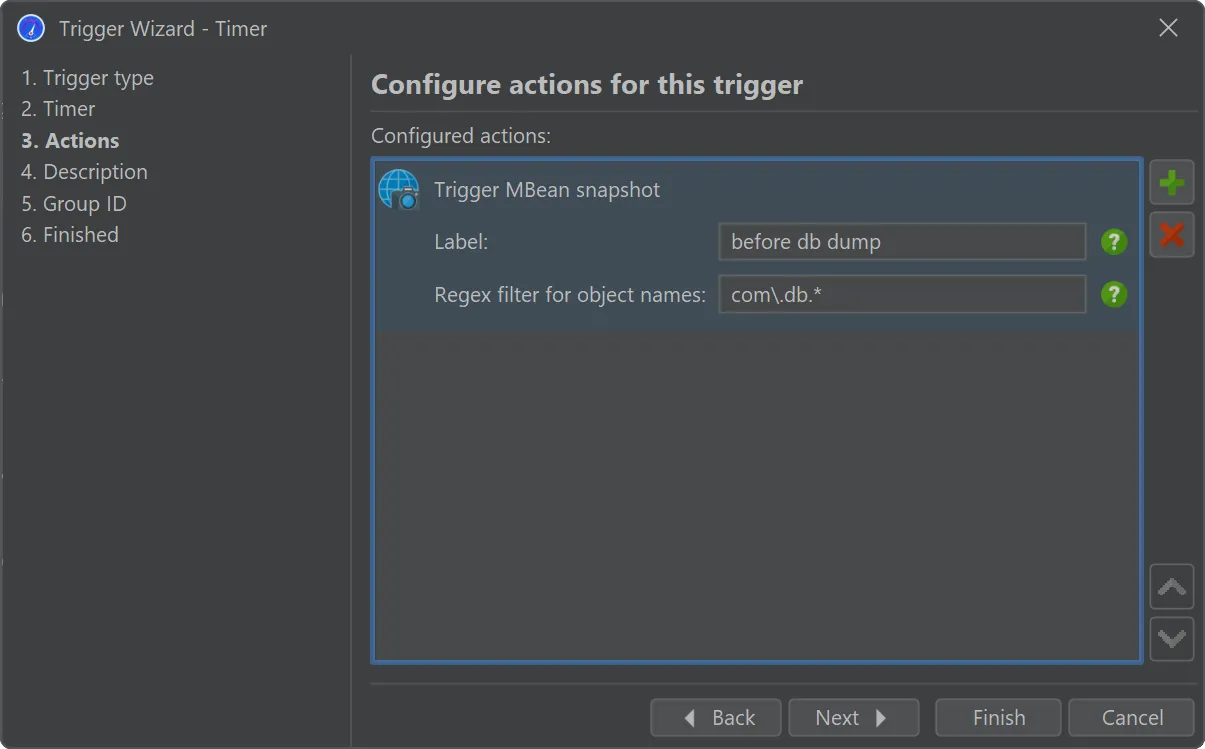
In the MBean snapshot trigger action, you can set a label as well as a filter for the included MBeans as well.
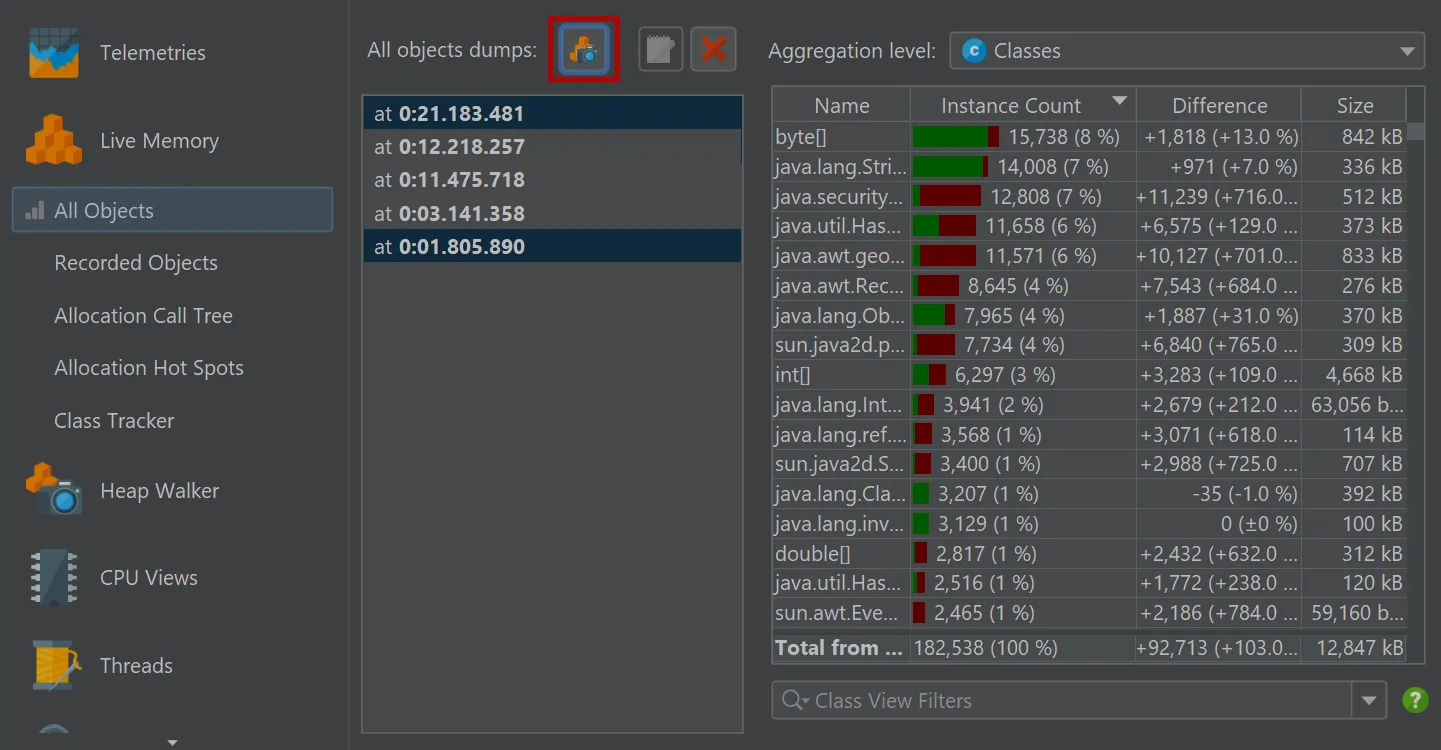
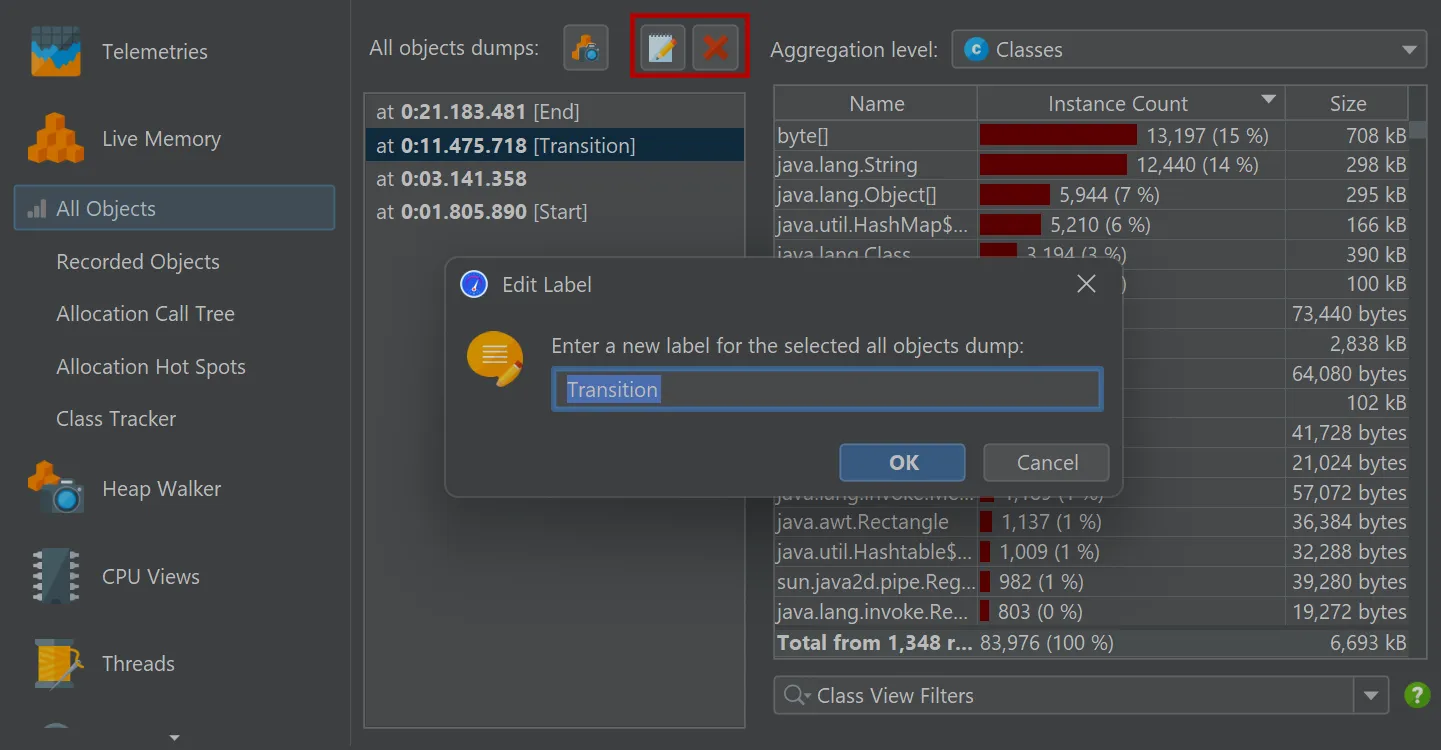
You can now take multiple "all objects" dumps.
The "All objects" view now has an action to take snapshots of the class histogram for all objects on the heap.
When two dumps are selected, the differences are shown in the view.
The toolbar above the dump selector offers actions to label and remove selected dumps.
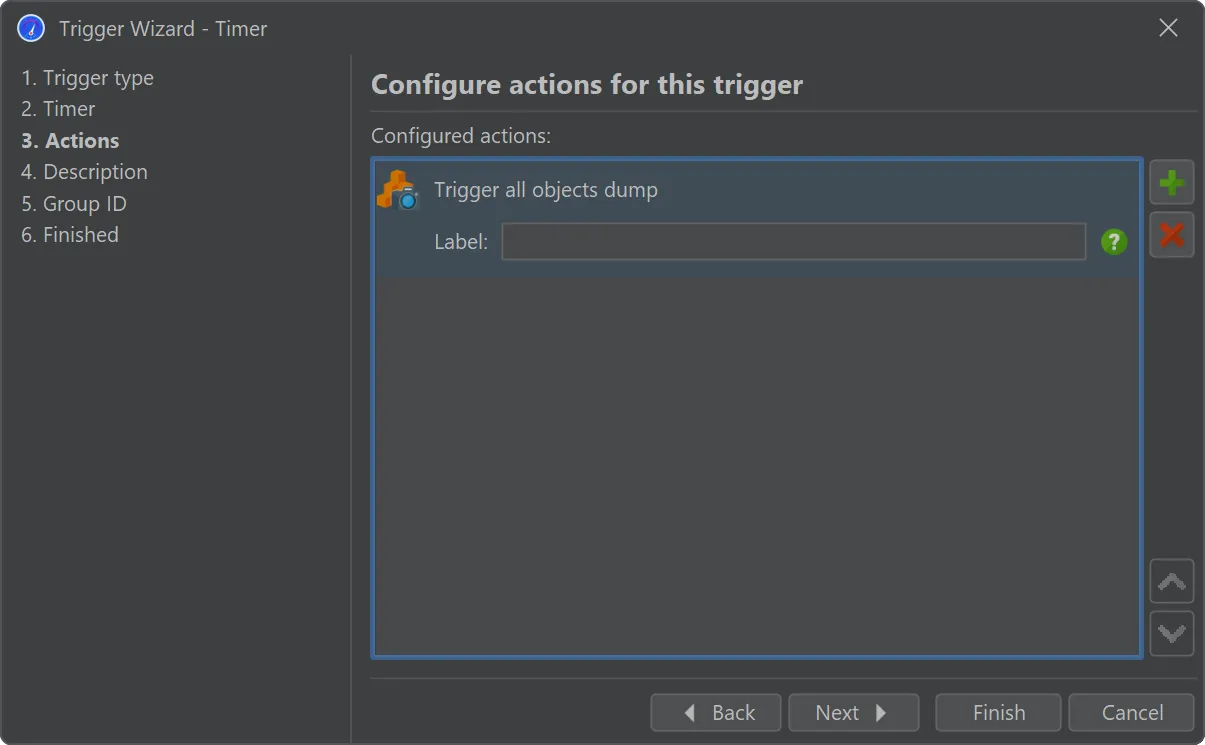
A trigger action has been added to take all object dumps programmatically, either in live mode or during offline profiling.
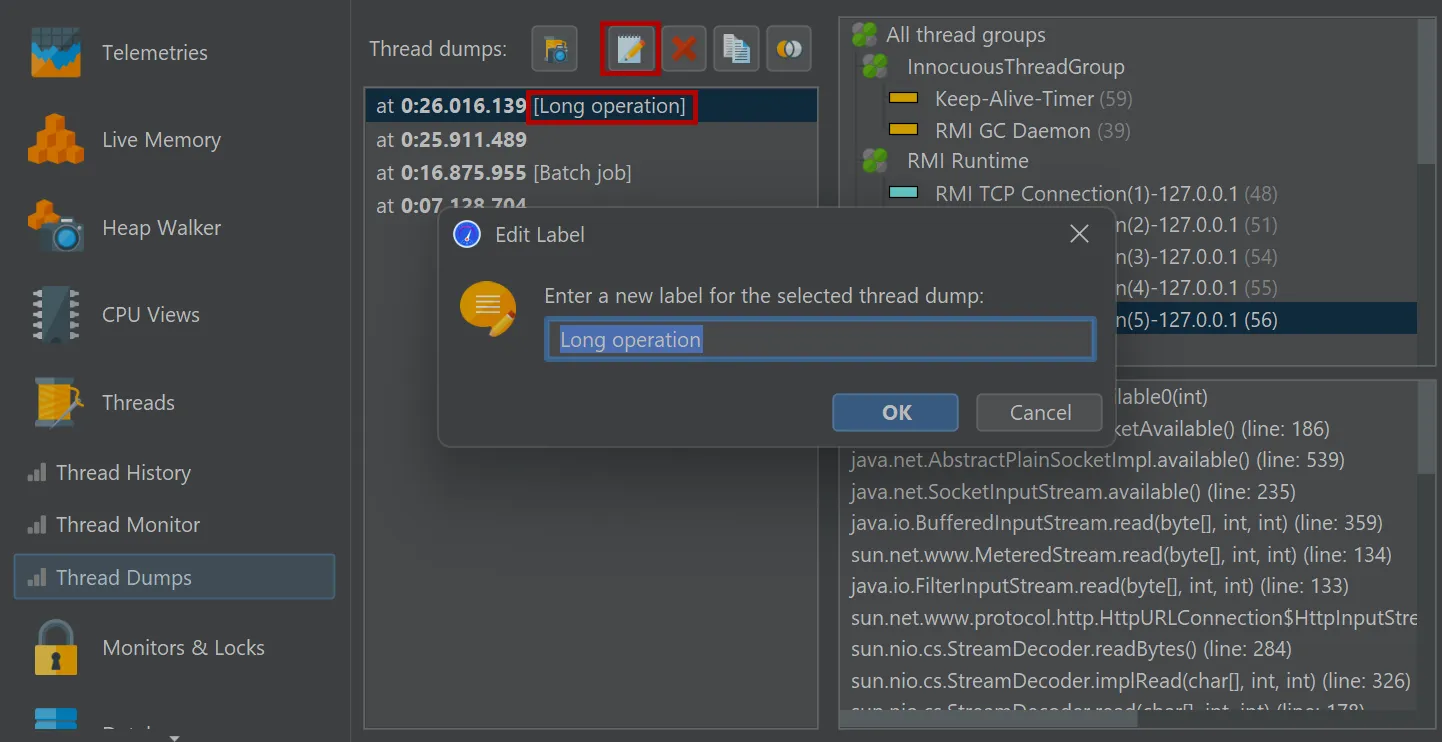
On a related note, it is now possible to label dumps in the thread dumps view as well.
This can also be done via the trigger action and the Controller API.
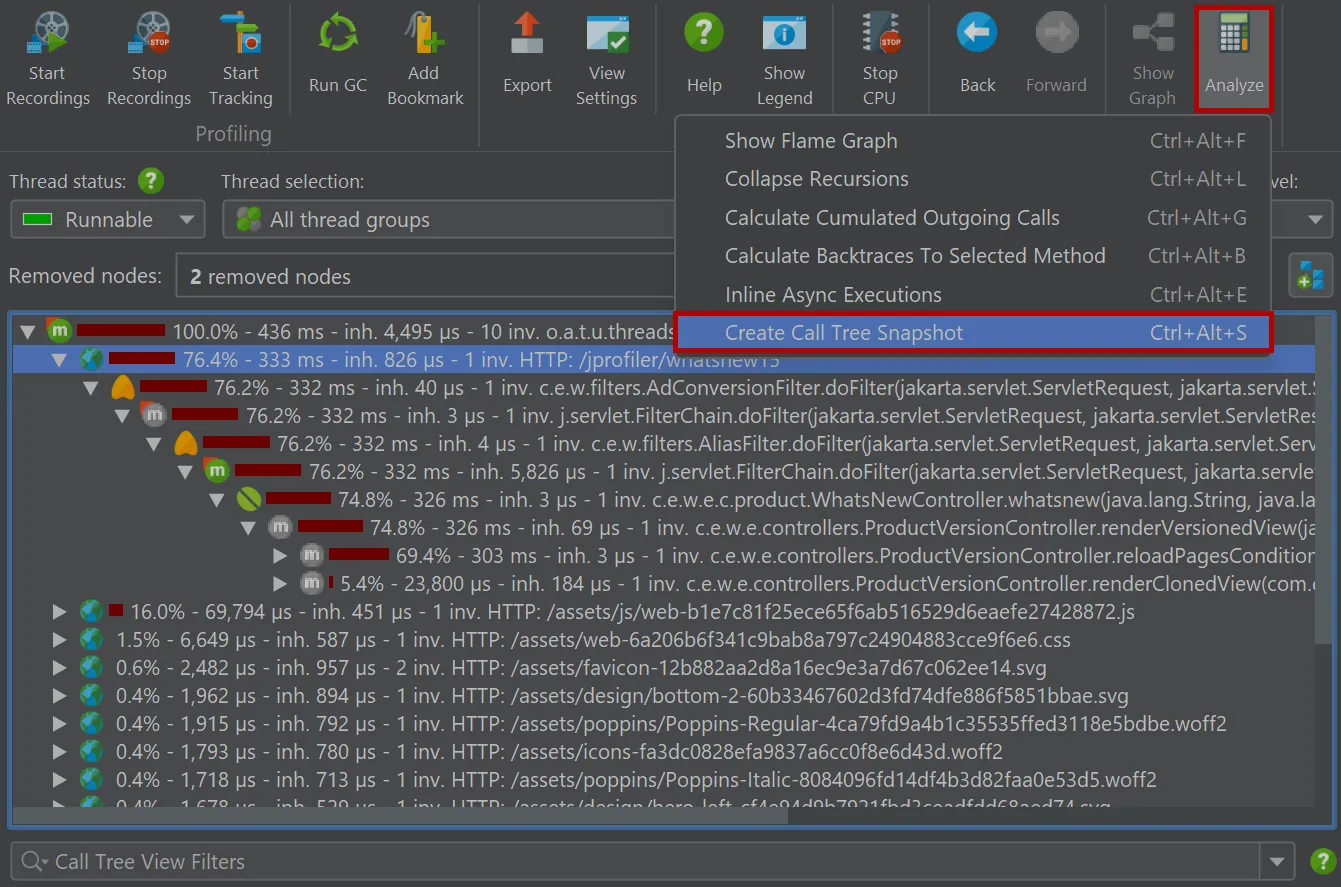
You can now make snapshots of the "Call tree" view in the CPU section.
For that purpose, a "Call tree snapshot" action has been added to the call tree analyses drop-down.
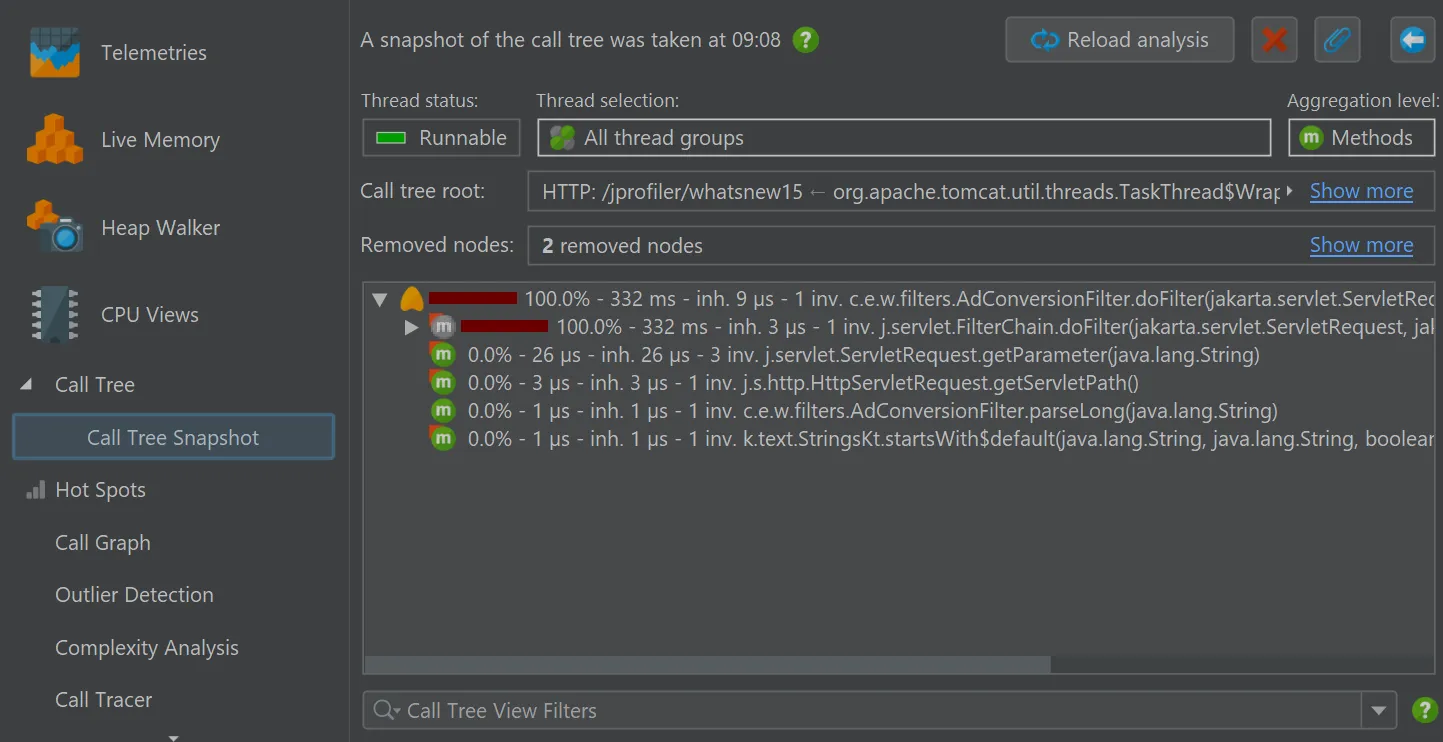
It creates a new call tree analysis view below the main call tree view that shows a static copy of the selected root, or the entire
call tree if no node was selected. All other view parameters like thread status or aggregation level are fixed in the call tree snapshot.
Unlike other call tree analyses, call tree snapshots are saved into JProfiler snapshots, because they contain separate data.
With this tool, you can manage different call tree recordings without resorting to saving full snapshots that you have to open in
different JProfiler windows. Instead, you can remain in the same live session and keep different sets of recording data around.
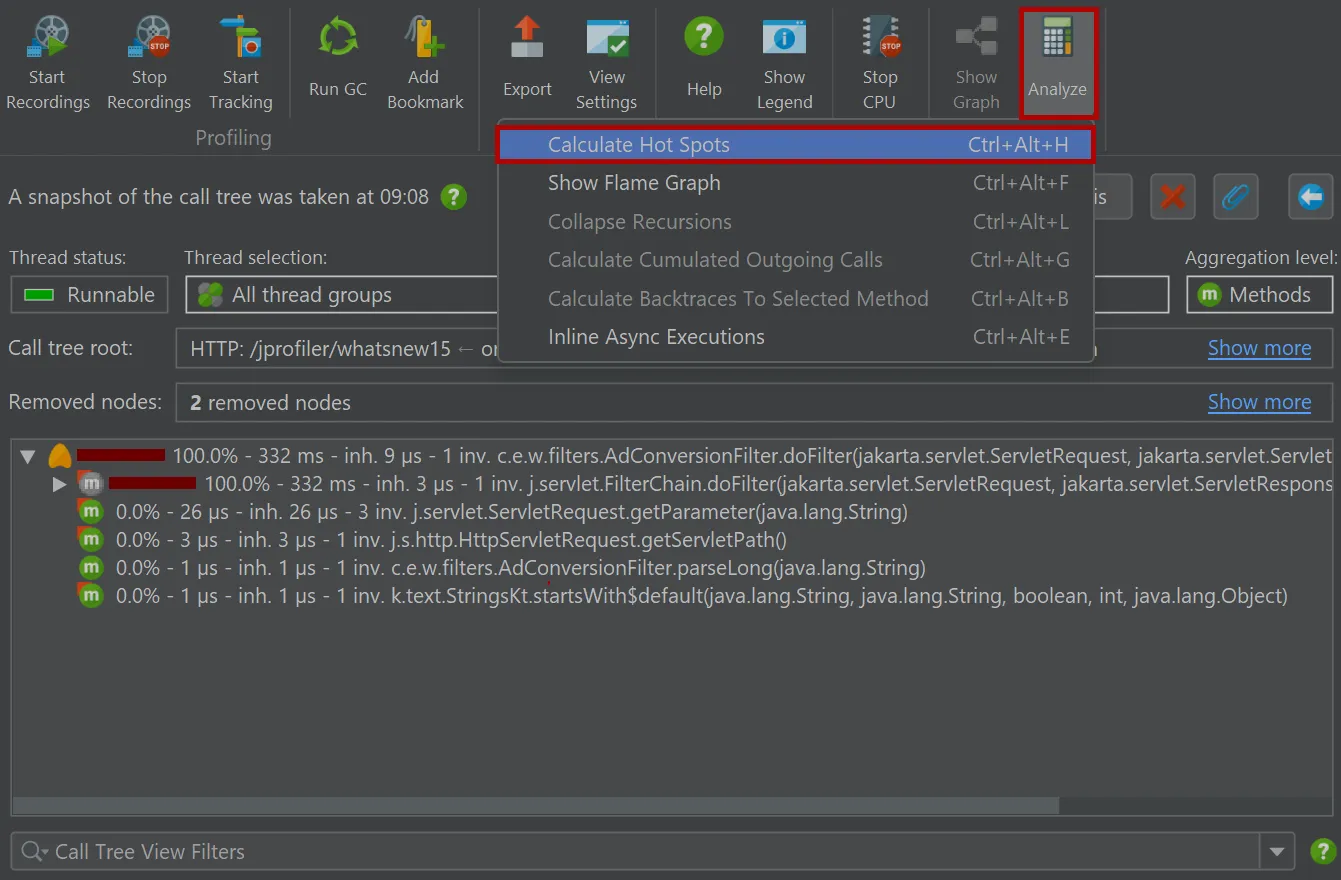
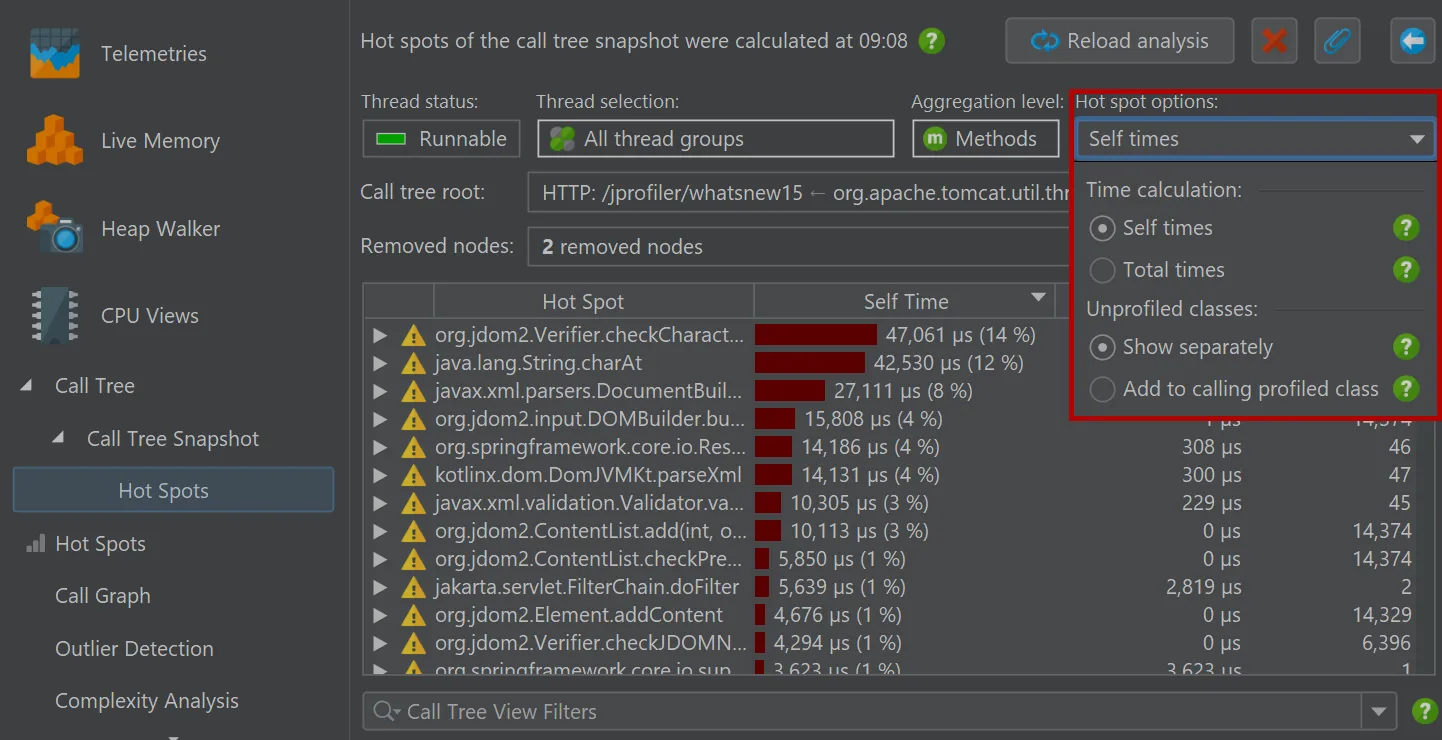
In the call tree snapshot view, a "Calculate hot spots" analysis action is available besides the usual call tree analysis types.
The resulting hot spot view is added as a child of the call tree snapshot view and shows the static hot spots for the data in the parent
view. The hot spot calculation options are still adjustable here.
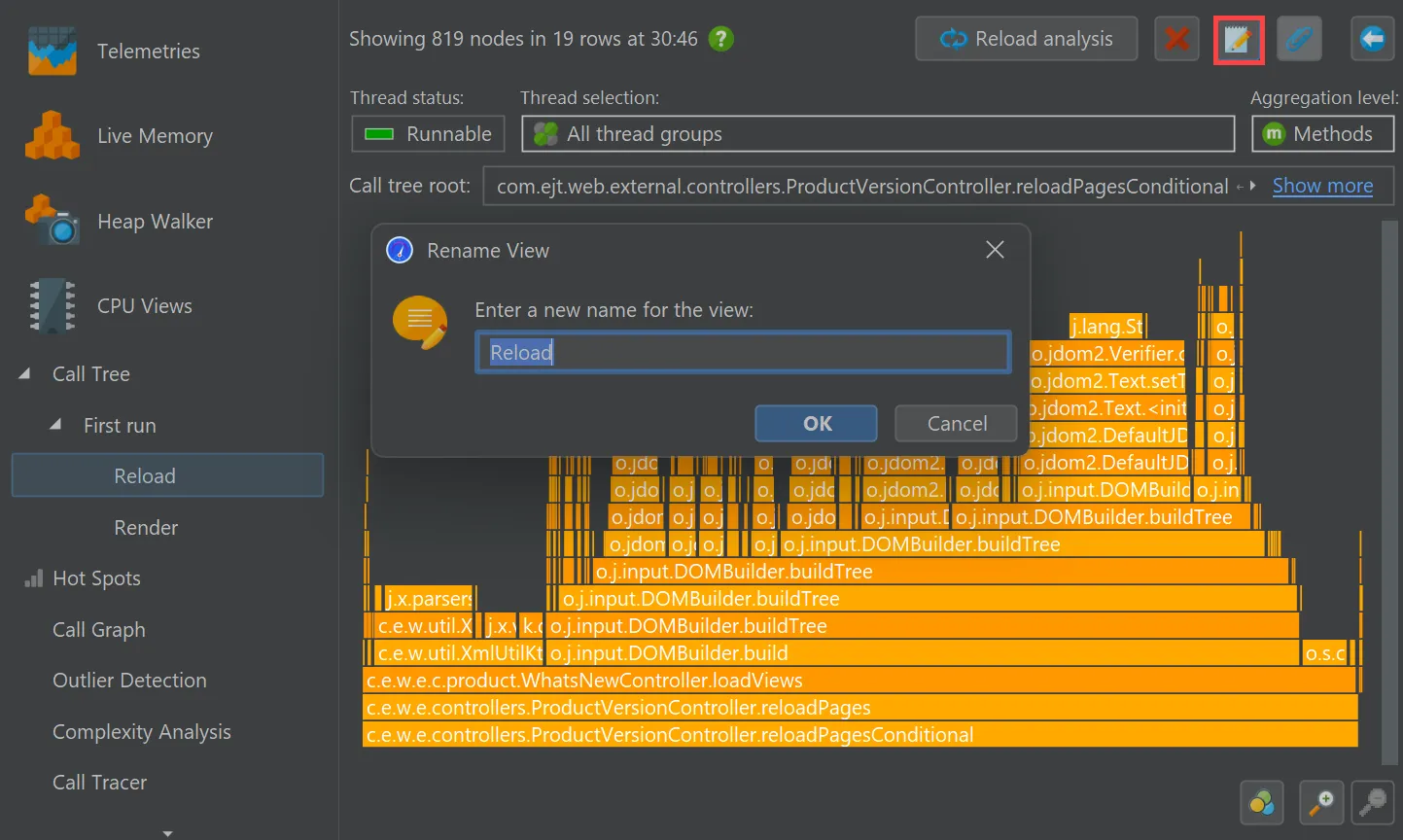
Call tree analyses have been improved.
You can now rename call tree analyses. After making them permanent with the pin button, a rename button will appear that changes
the name of the analysis in the view selector.
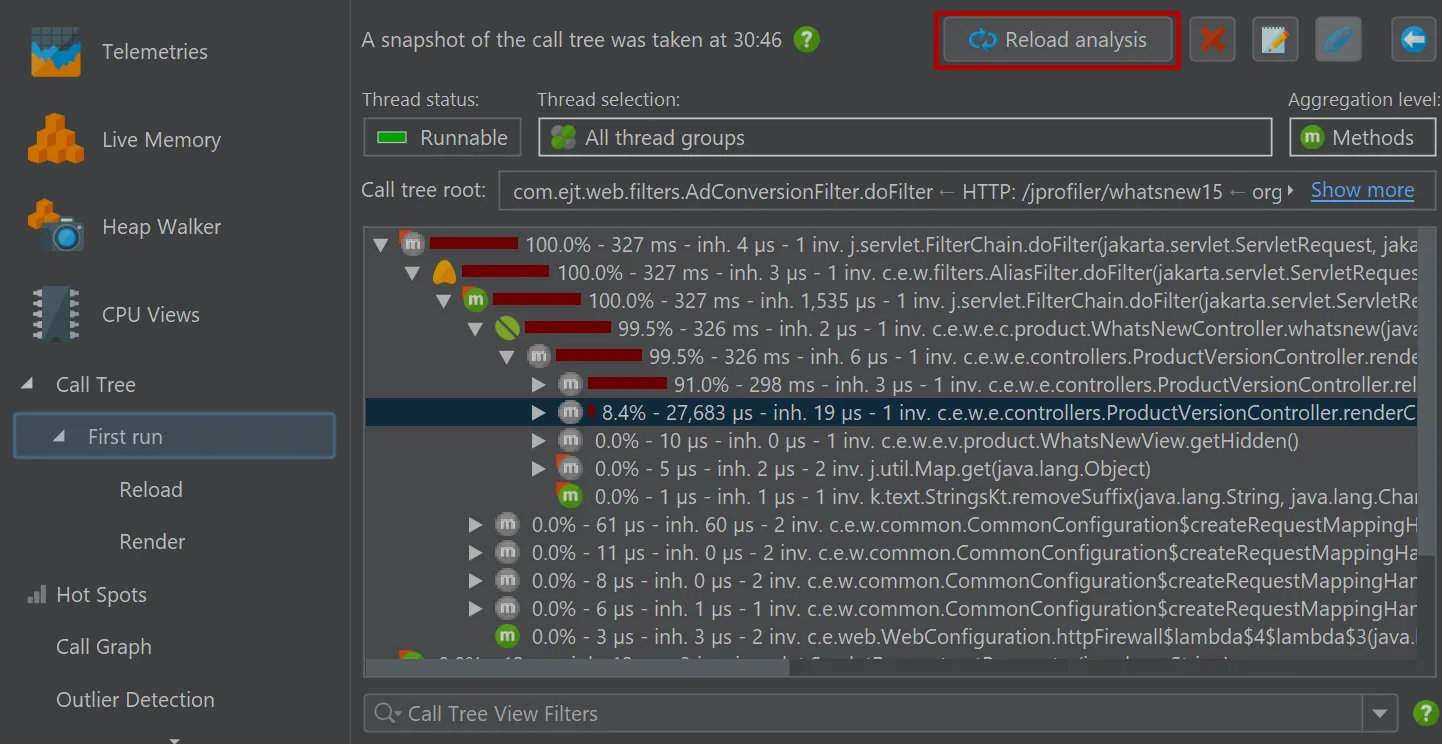
In addition, the "Reload analysis" button goes back to the top level ancestor view and re-calculates all ancestor views
and all descendant views for the new data. In the example below, the current data in the live call tree would be used to update the
call tree view labeled "First run" and then the flame graph views labeled "Reload" and "Render".
Heap walker filter and grouping scripts on dumped data have been added.
Previously, only filter and grouping scripts on live objects were available which did not work for snapshots. Also, changing data
and garbage collection of objects may require operations on dumped data instead of live data.
In the references view of the heap walker, the "Apply filter" dropdown contains a new action to filter objects by running a script on
dumped data.
In the script editor, objects from the com.jprofiler.api.agent.heap API are passed as an argument, and the boolean return value
of the script decides whether the object is included in the new object set.
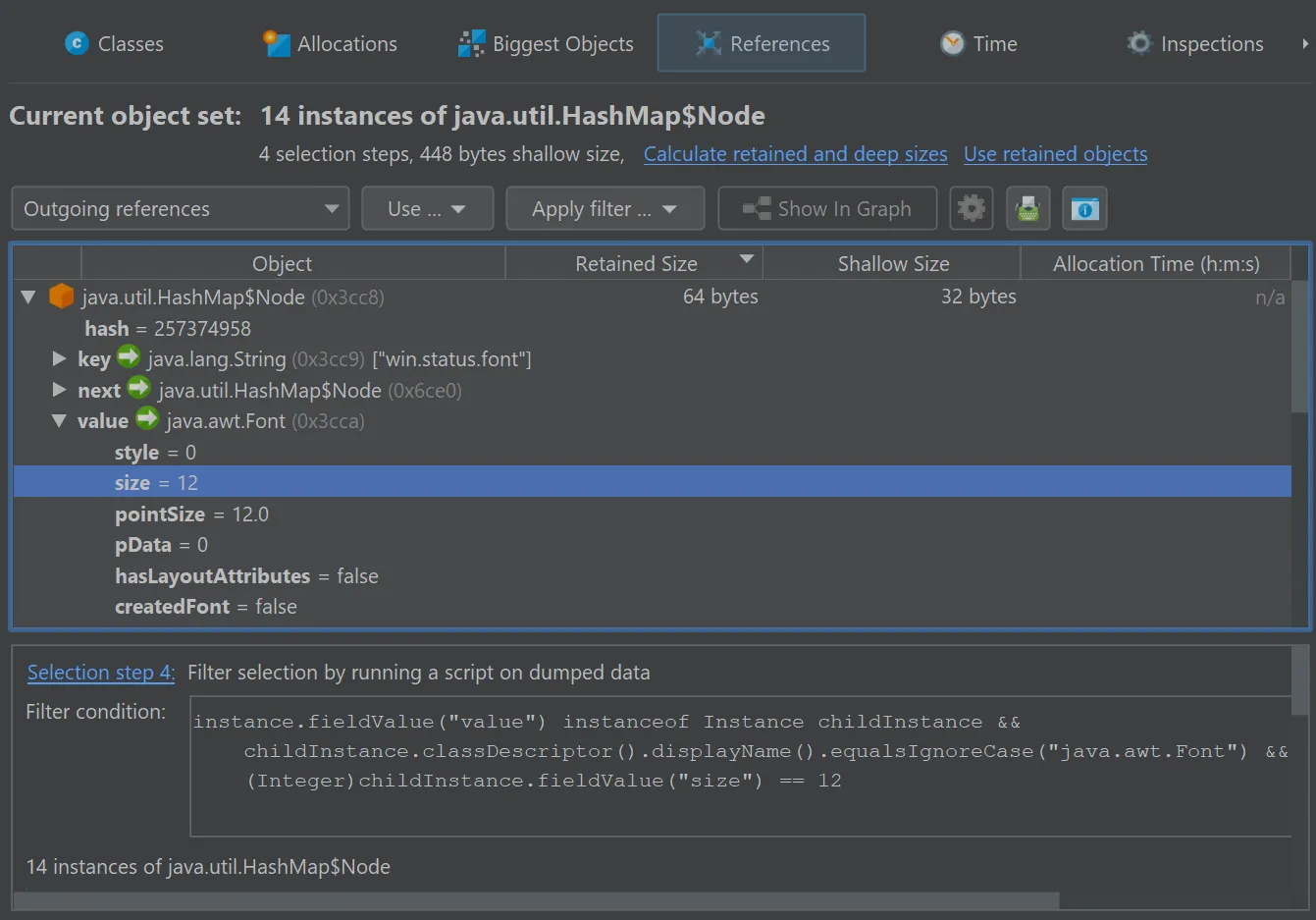
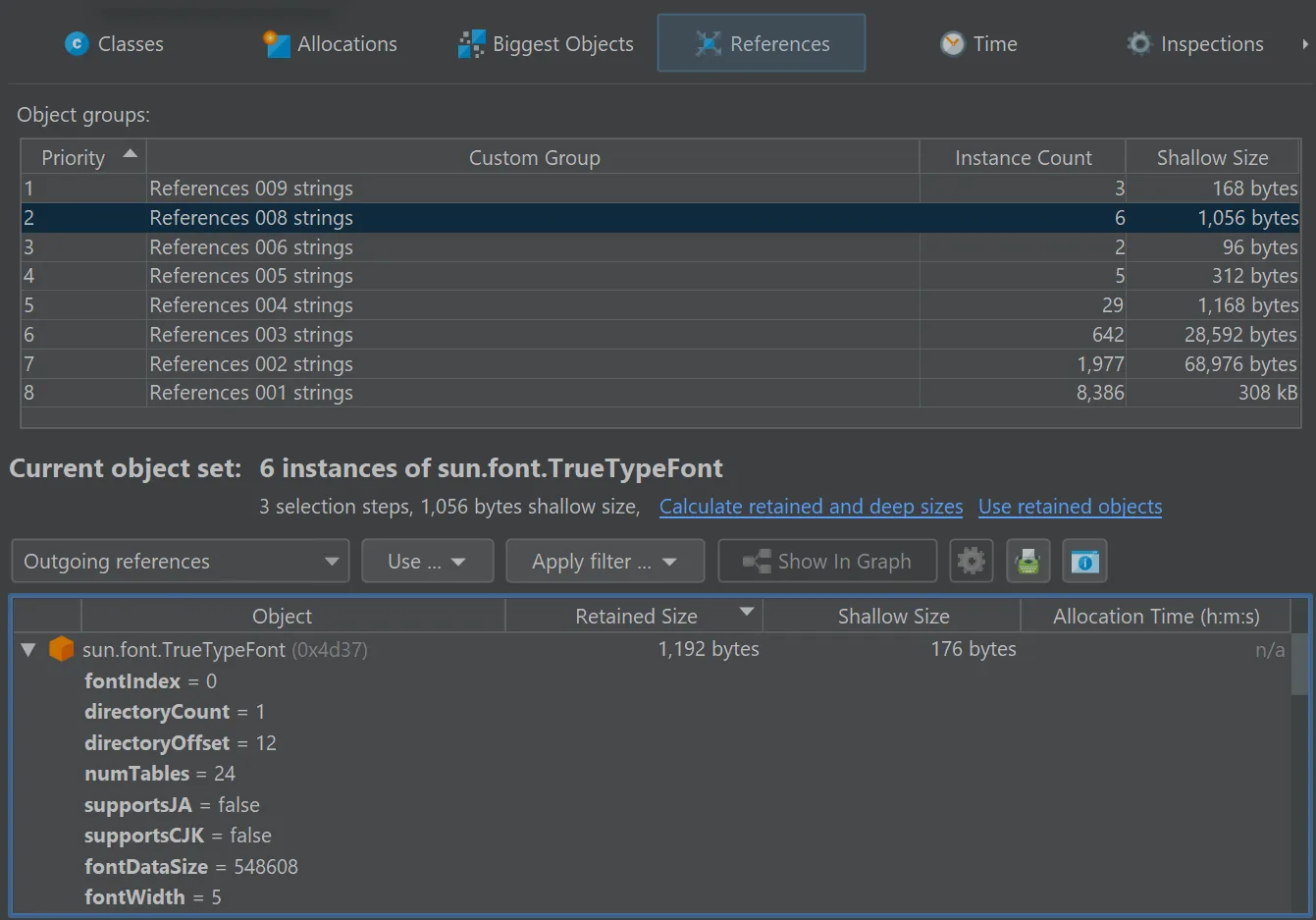
In general, the parameter is of type com.jprofiler.api.agent.heap.HeapObject but can be narrowed to a subtype if the current
object set allows it. In the screenshot below, the current object set only contained java.util.HashMap$Node instances, so the
parameter is of type com.jprofiler.api.agent.heap.Instance which provides access to field values.
The script selects java.util.HashMap$Node instances whose value is a java.awt.Font with a size of 12.
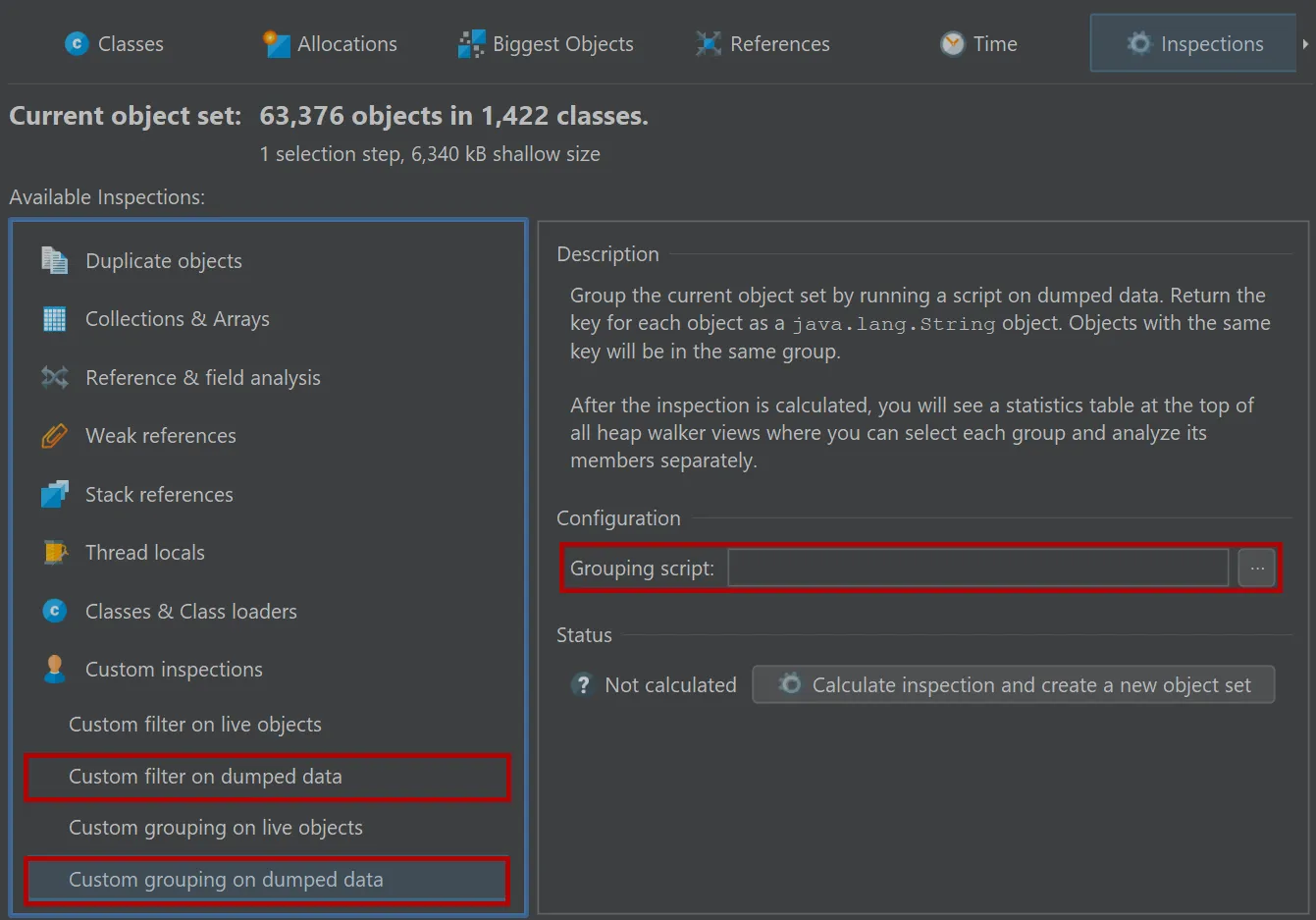
In addition to the filter script in the references view, JProfiler provides an inspection to filter all objects in the current
object set as well an inspection which groups all objects according to the string return value of a script.
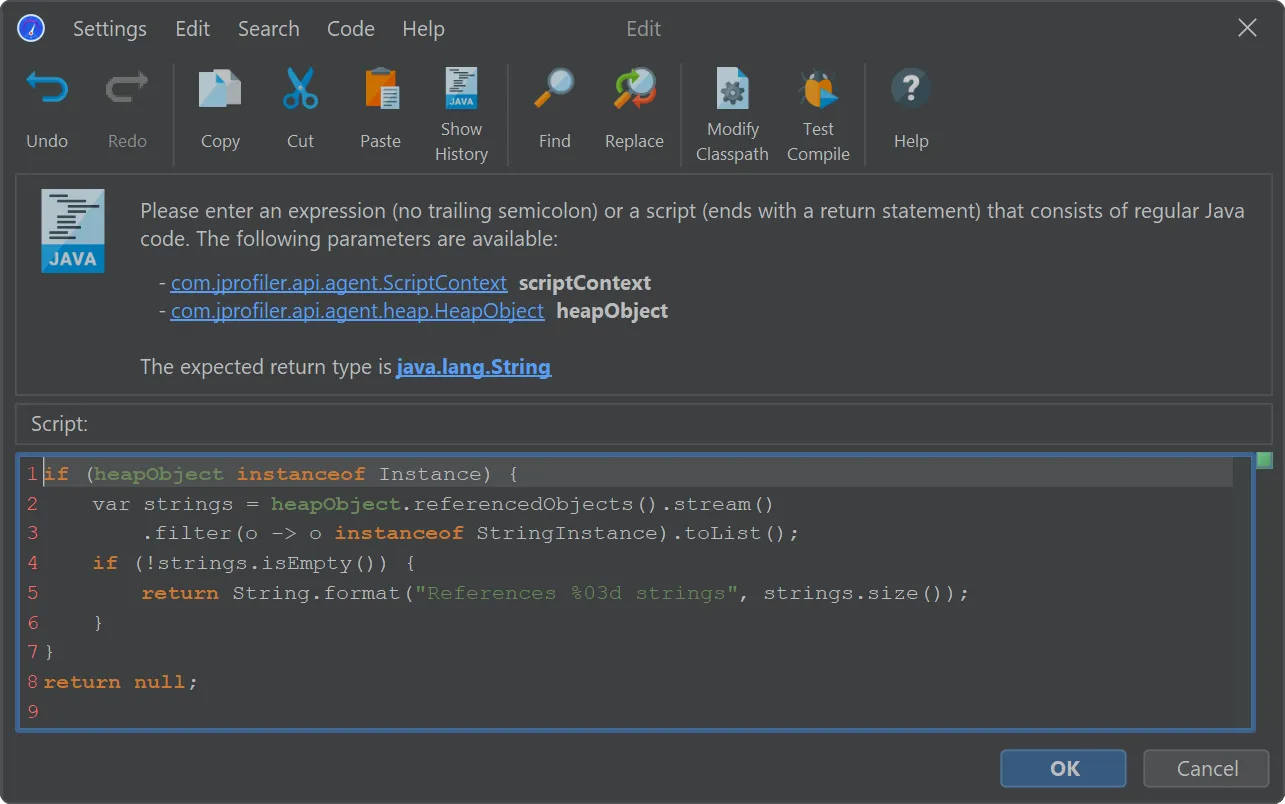
In the "Custom grouping on dumped data" script below, all regular instances are grouped by the number of strings that they reference.
If the passed object is not a regular instance or if it does not reference any strings, the script returns null and the object
is not included.
As for other kings of groupings, a grouping selector is shown at the top after the inspection has been calculated. When you select a group
row, the current heap walker view will only show the instances that are contained in that group.
JProfiler 15 makes it easier to see which views contain data.
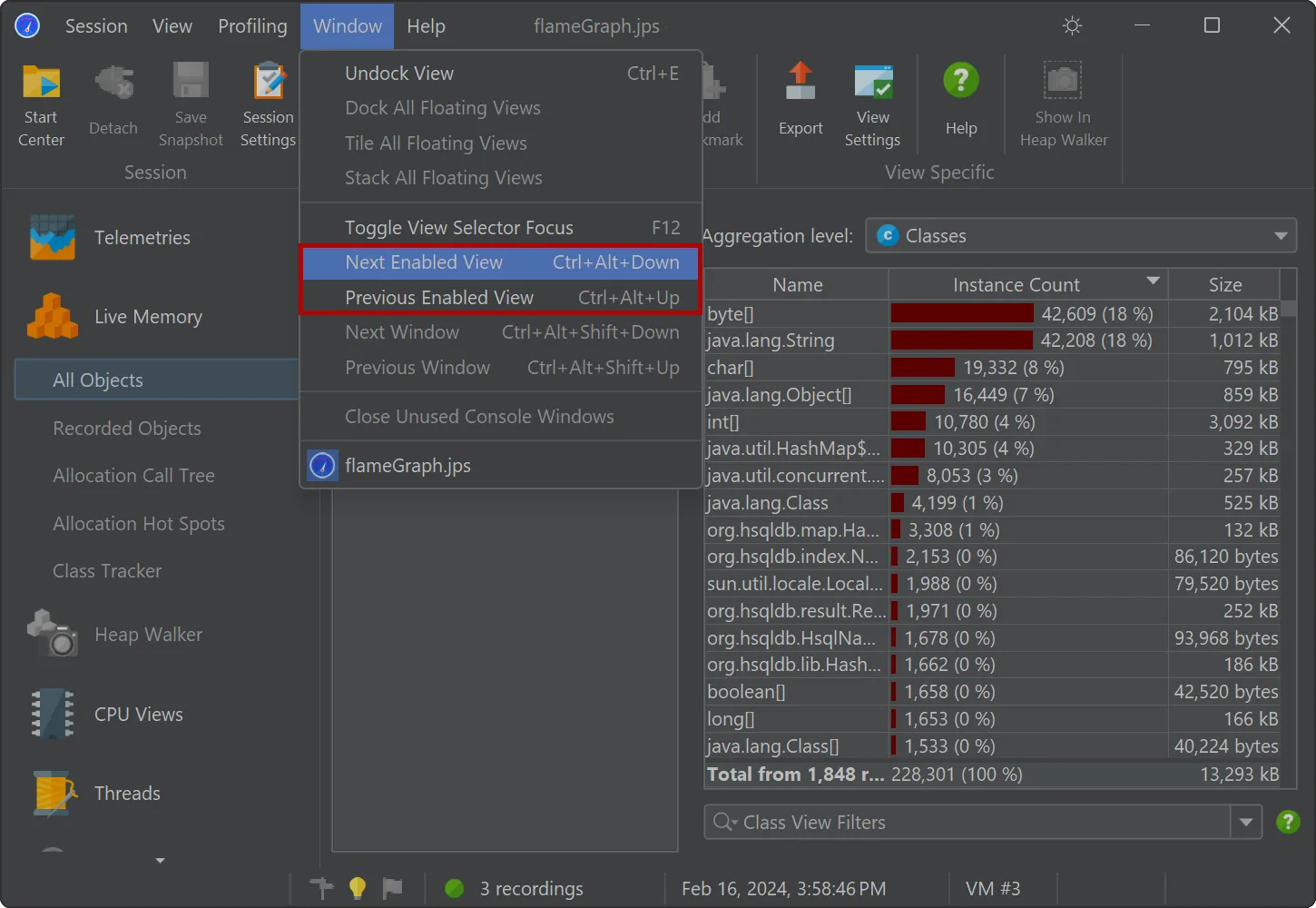
For snapshots, all views without recorded data are now shown as disabled in the view selector.
With the new "Next enabled view" and "Previous enabled view" actions, you can quickly step through all relevant views.
For live sessions, the views displaying recorded data now have a special marker in front of the view name.
A Japanese locale has been added. こんにちは、日本!
The UI as well as the documentation have been fully localized into Japanese.
The language can be changed in the general settings and will be auto-detected by the installer.
A Korean locale has been added. 안녕하세요, 한국!
The UI as well as the documentation have been fully localized into Korean.
The language can be changed in the general settings and will be auto-detected by the installer.
Thread IDs are now shown in the UI.
Previously, only thread names were displayed which are not necessarily unique. Now the unique ID of each thread is added, so that
you can identify particular threads under all circumstances.
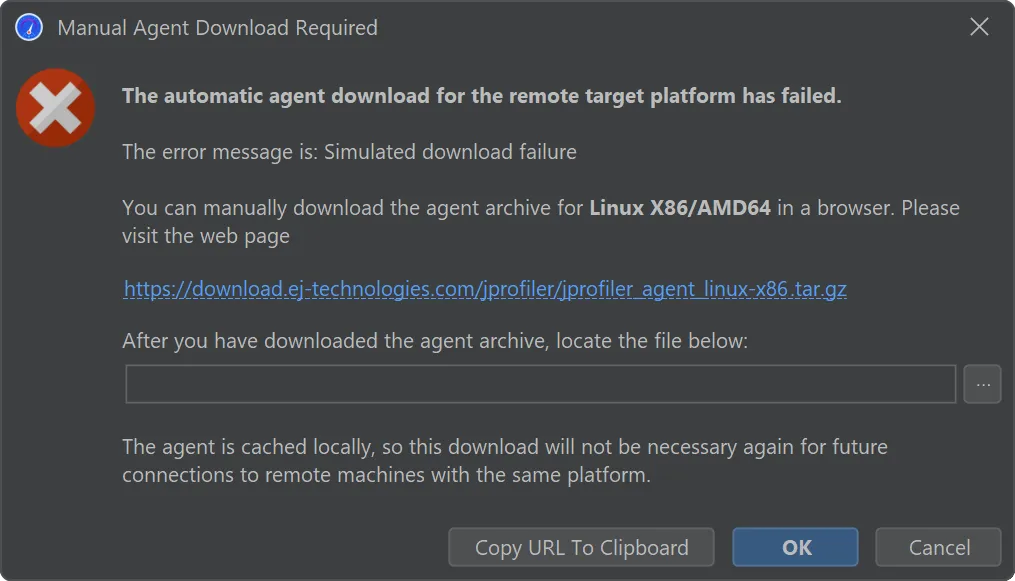
The process for handling a download failure of JProfiler agent archives for remote profiling has been improved.
During a zero-configuration remote attach operation, JProfiler needs to upload the profiling agent for the remote platform.
If the agent for the remote architecture is not available, JProfiler will download and cache it locally. In the case of restrictive
firewalls, such a download may not be possible.
While previous workarounds were cumbersome, JProfiler 15 now offers a workflow for procuring the agent archive with a browser and
telling JProfiler about the externally downloaded archive.