对于小型堆,获取堆快照只需几秒钟,但对于非常大的堆,这可能是一个漫长的过程。物理内存不足会使计算变得更慢。例如,如果JVM有50 GB的堆,而您在本地机器上分析堆转储时只有5 GB的可用物理内存,JProfiler无法在内存中保存某些索引,处理时间会不成比例地增加。
因为JProfiler主要使用本机内存进行堆分析,所以不建议增加-Xmx值在bin/jprofiler.vmoptions文件中,除非您遇到了OutOfMemoryError并且JProfiler指示您进行这样的修改。如果本机内存可用,它将自动使用。分析完成并构建内部数据库后,本机内存将被释放。
对于实时快照,分析在获取堆转储后立即计算。当您保存快照时,分析将保存到快照文件旁边带有后缀.analysis的目录中。当您打开快照文件时,堆遍历器将非常快速地可用。如果您删除.analysis目录,打开快照时将重新进行计算,因此如果您将快照发送给其他人,您不必将分析目录一起发送。
如果您想在磁盘上节省内存或生成的.analysis目录不方便,您可以在常规设置中禁用它们的创建。
HPROF快照和使用离线分析保存的JProfiler快照旁边没有.analysis目录,因为分析是由JProfiler
UI执行的,而不是由分析代理执行的。如果您不想在打开此类快照时等待计算,可以使用 jpanalyze命令行可执行文件来预分析快照。
建议从可写目录中打开快照。当您打开没有分析的快照且其目录不可写时,将使用临时位置进行分析。然后每次打开快照时都必须重复计算。
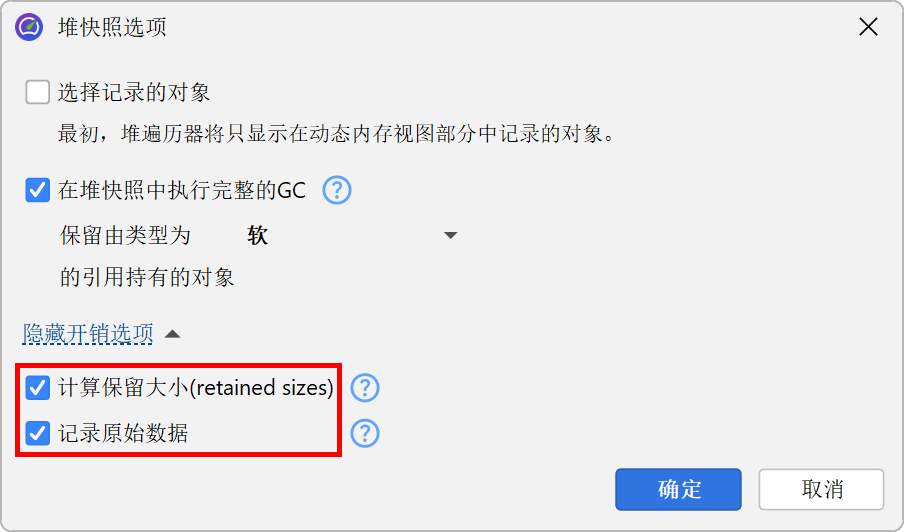
分析的一个重要部分是保留大小的计算。如果处理时间过长且您不需要保留大小,您可以在堆遍历器选项对话框的开销选项中禁用它们的计算。在这种情况下,“最大对象”视图也将不可用。不记录原始数据会使堆快照更小,但您将无法在引用视图中看到它们。如果您在文件选择对话框中选择自定义分析,打开快照时会显示相同的选项。